さて。このAI全盛期、我が社でも例に漏れずAIをうまく使っていこうという流れがきているため、AIを使った技術の検証をしてみようと思います。
どうせなら自分に身近なテーマを、ということで長らく趣味で習っているヴァイオリンのピッチ判定ができたら面白そうです。
調べてみたところいくつか使えそうなAIモデル(CREPE、Basic Pitch)があったため使えるか検証していきます。
また、比較用としてAIを使っていない従来の方式のaubioも試してみましょう。
はてさて、全てうまく動くでしょうか...。
環境構築
1. CREPE
READMEを見ながらインストールを進めると以下のエラーになりました。
ModuleNotFoundError: No module named 'pkg_resources'
仮想環境にsetuptoolsは入っているのですが...。
改めてGitHubから直接インストールしてみたり、setuptoolsの古いバージョンを使ってみたりと色々試してみたのですが変わらず同じエラーになりました。
改めてREADMEを確認してみたところ、Python3.6, 3.7の記載がありコード自体も長らくメンテナンスされていないようで環境構築が難しそうです。
今回はCREPEの使用を断念しました。
2. aubio
こちらもインストールでエラーです。
python/ext/ufuncs.c:48:3: error: incompatible function pointer types initializing
'PyUFuncGenericFunction' (aka 'void (*)(char **, const long *, const long *, void *)')
with an expression of type 'void (*)(char **, npy_intp *, npy_intp *, void *)'
どうやら新しいnumpyとの互換性がないようです。
aubioの使用も今回は諦めることにします。
3. Basic Pitch
Mac M1を使っているのですが、その場合PythonはVer.3.10を使う必要があるようです。
3.10で構築を進めます。
$ conda create -n violin-pitch python=3.10
$ conda activate violin-pitch
$ pip install basic-pitch
warningが出たので以下もインストール
$ pip install 'basic-pitch[onnx]'
こちらはエラーが出ずうまくいきました。
早速動くか試してみましょう。
練習時に後から客観的に聞いて確認する用に録画していたものがあるので、そちらの冒頭を切り出し、m4aで保存したものを読み込ませてみます。
$ basic-pitch output/ test.m4a
---省略---
ModuleNotFoundError: No module named 'pkg_resources'
またこのエラーです。
エラー全体をよくみると今度はresampyというライブラリでエラーが出ているようです。
試しにresampyのバージョンを落としてみましたが同じエラー。
pkg_resourcesは新しいsetuptoolsではimportlib.metadataに置き換えられているため、利用箇所を書き換えることでうまくいくかもしれません。
強引ですが、試してみます。
ファイルの場所を確認
$ python -c "import resampy; print(resampy.__file__)"
該当箇所を書き換え
$ sed -i '' 's/import pkg_resources/import importlib.metadata as pkg_resources/' /opt/anaconda3/envs/violin-pitch/lib/python3.10/site-packages/resampy/filters.py
再度実行
$ basic-pitch output/ test.m4a
今度はうまくいきました!
生成されたtest_basic_pitch.midを確認してみます。
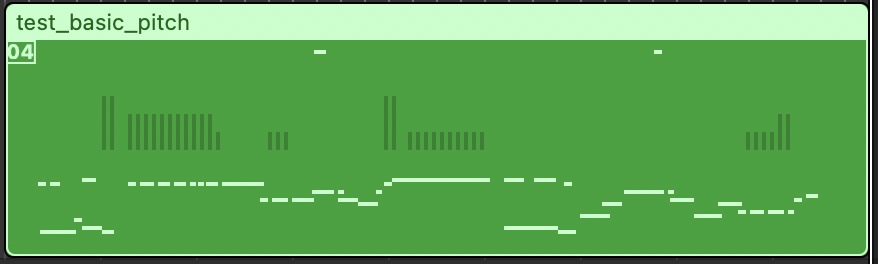
音程が検出されていますね。
元の音源と聴き比べてみます。
- 音は概ねあっていそう
- 自分の演奏でピッチが微妙にずれている箇所はMIDIでも正しくない音程として検出されており、精度は高そう
- 装飾音の部分は正しく取れてない
- ビブラート部分は音が揺れている
きちんと使えそうなのでこちらを使用し、色々検証していきます。
検証① : 電子ピアノの音階検出
まずは確実に正しい音程を検出できるであろう電子ピアノから。
中央Cから1オクターブの音階で確認します。
我が家にある電子ピアノは内部メモリに録音し、それをUSBに移すこともできるのですが、今回はヴァイオリンと録音環境を揃えるためQuickTime Playerで録音します。
(内部メモリ→USBで移したデータは.MIDになっていました。最初から正確なMIDIがわかっているので今回の検証には不向きと判断しました)
import sys
from basic_pitch.inference import predict
from basic_pitch import ICASSP_2022_MODEL_PATH
# 正解の音名リスト(ドレミファソラシド)
EXPECTED_NOTES = ['C4', 'D4', 'E4', 'F4', 'G4', 'A4', 'B4', 'C5']
def midi_to_note(midi_number):
note_names = ['C', 'C#', 'D', 'D#', 'E', 'F', 'F#', 'G', 'G#', 'A', 'A#', 'B']
note = note_names[midi_number % 12]
octave = (midi_number // 12) - 1
return f"{note}{octave}"
def analyze(audio_file):
_, _, note_events = predict(audio_file)
# 検出された音名を時間順に重複除去して取得
detected = []
prev_note = None
for note in note_events:
_, _, pitch_midi, confidence, _ = note
note_name = midi_to_note(round(pitch_midi))
if note_name != prev_note:
detected.append(note_name)
prev_note = note_name
print(f"\n検出された音: {detected}")
print(f"正解: {EXPECTED_NOTES}")
print()
correct = 0
for i, expected in enumerate(EXPECTED_NOTES):
if i < len(detected):
is_correct = detected[i] == expected
if is_correct:
correct += 1
mark = "✅" if is_correct else "❌"
print(f"{i+1}音目: 検出={detected[i]:<4} 正解={expected:<4} {mark}")
else:
print(f"{i+1}音目: 検出=なし 正解={expected:<4} ❌")
print(f"\n正答率: {correct}/{len(EXPECTED_NOTES)} = {correct/len(EXPECTED_NOTES)*100:.1f}%")
if __name__ == "__main__":
analyze(sys.argv[1])
まさかの結果
電子ピアノでの音階の録音も完了し、いざ、実行です。
検出された音: ['D2', 'C5', 'B4', 'A4', 'G4', 'D#2', 'F4', 'E4', 'D4', 'D5', 'C4', 'G1', 'D2', 'G5', 'A1', 'D2', 'D5']
正解: ['C4', 'D4', 'E4', 'F4', 'G4', 'A4', 'B4', 'C5']
1音目: 検出=D2 正解=C4 ❌
2音目: 検出=C5 正解=D4 ❌
3音目: 検出=B4 正解=E4 ❌
4音目: 検出=A4 正解=F4 ❌
5音目: 検出=G4 正解=G4 ✅
6音目: 検出=D#2 正解=A4 ❌
7音目: 検出=F4 正解=B4 ❌
8音目: 検出=E4 正解=C5 ❌
正答率: 1/8 = 12.5%
なぜ!?
ピアノはヴァイオリンのように押さえる場所によって音が変わることはない、Cの鍵盤からはCの音が、Dの鍵盤からはDの音が出る楽器です。
100%にならないとおかしいはずです。
一体何がいけなかったんだ...。とりあえず生の検出データを見てみます。
開始時間 終了時間 MIDI 音名 確信度
---------------------------------------------
19.69 19.92 38.0 D2 0.334
18.04 19.90 72.0 C5 0.841
16.87 18.04 72.0 C5 0.826
14.60 16.82 71.0 B4 0.798
12.57 14.61 69.0 A4 0.838
10.57 12.55 67.0 G4 0.835
10.55 10.98 39.0 D#2 0.365
8.32 10.56 65.0 F4 0.826
6.17 8.31 64.0 E4 0.835
4.24 6.15 62.0 D4 0.806
4.19 4.55 74.0 D5 0.394
2.24 4.17 60.0 C4 0.779
1.51 1.65 31.0 G1 0.388
0.73 0.91 31.0 G1 0.471
0.17 0.48 38.0 D2 0.413
16.89 17.68 38.0 D2 0.453
14.67 15.14 38.0 D2 0.465
6.23 6.55 38.0 D2 0.395
10.59 10.79 79.0 G5 0.377
1.27 1.64 33.0 A1 0.304
4.23 4.50 38.0 D2 0.363
5.46 6.11 74.0 D5 0.348
時系列がバラバラなのと低確信度が混ざっていることが問題になっていそうです。
データを見ると0.7未満のものをノイズとして扱って良さそうです。
一旦0.7を閾値として採用し、コードを修正してみます。
コードの修正と再実行
# 時間順にソート
sorted_events = sorted(note_events, key=lambda x: x[0])
detected = []
prev_note = None
for note in sorted_events:
start, end, pitch, confidence, _ = note
# 確信度が0.7未満のものを除外
if confidence < 0.7:
continue
note_name = midi_to_note(round(pitch))
if note_name != prev_note:
detected.append(note_name)
prev_note = note_name
さあ、実行してみましょう。これでいけるはずです。
検出された音: ['C4', 'D4', 'E4', 'F4', 'G4', 'A4', 'B4', 'C5']
正解: ['C4', 'D4', 'E4', 'F4', 'G4', 'A4', 'B4', 'C5']
1音目: 検出=C4 正解=C4 ✅
2音目: 検出=D4 正解=D4 ✅
3音目: 検出=E4 正解=E4 ✅
4音目: 検出=F4 正解=F4 ✅
5音目: 検出=G4 正解=G4 ✅
6音目: 検出=A4 正解=A4 ✅
7音目: 検出=B4 正解=B4 ✅
8音目: 検出=C5 正解=C5 ✅
正答率: 8/8 = 100.0%
きました!100%、想定通りの結果です。
時間順にソートし、確信度が0.7未満のものを除外する、で良さそうです。
電子ピアノがうまくいったので次はヴァイオリンに行ってみたいと思います。
検証② : ヴァイオリンの音階検出
早速録音してきました。結果はどうでしょう...。
検出された音: ['C4', 'D4', 'E4', 'F4', 'G4', 'A4', 'B4', 'C5']
正解: ['C4', 'D4', 'E4', 'F4', 'G4', 'A4', 'B4', 'C5']
1音目: 検出=C4 正解=C4 ✅
2音目: 検出=D4 正解=D4 ✅
3音目: 検出=E4 正解=E4 ✅
4音目: 検出=F4 正解=F4 ✅
5音目: 検出=G4 正解=G4 ✅
6音目: 検出=A4 正解=A4 ✅
7音目: 検出=B4 正解=B4 ✅
8音目: 検出=C5 正解=C5 ✅
正答率: 8/8 = 100.0%
はい!うまい!!
いや、流石にC-Dur1オクターブじゃそんな外すことないですよね。
これだと結果的に面白くな...失礼、電子ピアノと比較しようという観点では同じ結果になってしまい、結局精度が良いのかどうかがわからないので、わざと少し外したバージョンと大袈裟に外したバージョンでも試してみようと思います。
検証③ : 音程を外すパターンの検証
音を少しだけ外してみる
まずは少し外したバージョンです。
「少し外す」というのが難しいのですが...チューナーを横目になるべくセントが±20~50になるあたりを狙ってみます。
※セントとは:半音を100等分したものが1セント。±50セント以内であればチューナー上で"その音"として表示される
※DとAは開放弦のため「音を外す」という行為の対象外とする
検出された音: ['C4', 'D4', 'G4', 'A4', 'B4', 'C5']
正解: ['C4', 'D4', 'E4', 'F4', 'G4', 'A4', 'B4', 'C5']
※今回のプログラムは検出した音を順番に正解と比べていくものになっており、音が抜け落ちると正誤が正しく判定できないため、検出された音と正解のリストのみ掲載します
E4とF4が検出されませんでした。
生のデータを確認したところ、少し外して弾いたことで確信度が0.7未満になり検出できなかったようです。
音を大袈裟に外してみる
今度は半音外すくらいの勢いで外してみます。
セントで言うと±51以上になるように意識しつつ...。
検出された音: ['C#4', 'D4', 'F#4', 'G4', 'A4', 'B4', 'C#5']
正解: ['C4', 'D4', 'E4', 'F4', 'G4', 'A4', 'B4', 'C5']
大袈裟に外したことで隣の音として検出され#が出現しました。
以上2つの検証結果から少し外すと確信度が0.7未満になり検出できず、大袈裟に外すと隣の音として誤検出されるということがわかりました。
音程のずれが大きいほど正答率が下がっており、Basic Pitchはある程度正しくピッチのずれを検知できる、と言えるかと思います。
検証④:実際の曲での検証
さて、音階でどうなるかの検証はできました。次は実際の曲でどうなるか試してみましょう。
今練習している曲の中で一番高音部で演奏される15小節で検証してみます。
音階の際には気持ちゆっくり、はっきりとを意識したのですが、今回は実際の曲なのでテンポは落とさず、ビブラートもかけて普段通り弾いてみます。
また、装飾音符は検出されないだろうという予想の元、正解を用意しました。
検出された音: ['A5', 'B5', 'C#6', 'D6', 'E6', 'D6', 'B5', 'C#6', 'A5', 'C#6', 'D6', 'F#6', 'D6', 'B5', 'C#6', 'A5', 'F#6', 'E6', 'D#6', 'E6', 'F#6', 'G6', 'F#6', 'E6', 'F#6', 'A6', 'B6', 'A6', 'E6']
正解: ['A5', 'B5', 'C#6', 'D6', 'E6', 'D6', 'C#6', 'B5', 'C#6', 'A5', 'A5', 'B5', 'C#6', 'D6', 'E6', 'D6', 'C#6', 'D6', 'F#6', 'E6', 'D6', 'C#6', 'B5', 'C#6', 'A5', 'F#6', 'E6', 'D#6', 'E6', 'F#6', 'G6', 'F#6', 'E6', 'F#6', 'G6', 'A6', 'B6', 'A6', 'G6', 'G6', 'F#6', 'E6', 'D6']
音数が足りてないです。少し外したのか、そもそも検出できていないのか...。
この結果の出し方だといまいち判断がしにくいですね。
念の為電子ピアノでも同じフレーズを試してみます。
電子ピアノで同じフレーズを検証してみる
早速電子ピアノで同じフレーズを弾いたものを録音し実行してみます。
検出された音: ['A5', 'B5', 'C#6', 'D6', 'C#6', 'B5', 'C#6', 'A5', 'B5', 'C#6', 'B5', 'C#6', 'A5', 'E6', 'A6', 'G6', 'E6', 'D6']
正解: ['A5', 'B5', 'C#6', 'D6', 'E6', 'D6', 'C#6', 'B5', 'C#6', 'A5', 'A5', 'B5', 'C#6', 'D6', 'E6', 'D6', 'C#6', 'D6', 'F#6', 'E6', 'D6', 'C#6', 'B5', 'C#6', 'A5', 'F#6', 'E6', 'D#6', 'E6', 'F#6', 'G6', 'F#6', 'E6', 'F#6', 'G6', 'A6', 'B6', 'A6', 'G6', 'G6', 'F#6', 'E6', 'D6']
全然検出されてませんね...。高い音域なのでそのせいでしょうか...?
1オクターブ下げてみます。
検出された音: ['A4', 'B4', 'C#5', 'D5', 'E5', 'D5', 'C#5', 'B4', 'C#5', 'A4', 'B4', 'C#5', 'D5', 'C#5', 'D5', 'F#5', 'E5', 'D5', 'C#5', 'B4', 'C#5', 'A4', 'F#5', 'E5', 'D#5', 'E5', 'F#5', 'G5', 'F#5', 'E5', 'F#5', 'G5', 'A5', 'B5', 'A5', 'G5', 'E5', 'D5']
正解: ['A4', 'B4', 'C#5', 'D5', 'E5', 'D5', 'C#5', 'B4', 'C#5', 'A4', 'A4', 'B4', 'C#5', 'D5', 'E5', 'D5', 'C#5', 'D5', 'F#5', 'E5', 'D5', 'C#5', 'B4', 'C#5', 'A4', 'F#5', 'E5', 'D#5', 'E5', 'F#5', 'G5', 'F#5', 'E5', 'F#5', 'G5', 'A5', 'B5', 'A5', 'G5', 'G5', 'F#5', 'E5', 'D5']
検出数が増えました。1オクターブ下げる前の生データを確認したところ、確信度0.6が増えていました。どうやら高音域だと全体的に少し確信度が下がり、検出されにくくなっているようです。
正解と見比べると一部例外はあるものの連続で2回同じ音を弾いている箇所が1回になっていたり、16分音符の部分で音が抜けていたりしました。
また、予想通り装飾音は検出されていませんでした。
連続で2回同じ音を弾いている箇所が1回になっていることに関しては、今回のピッチ検出用に書いたコードでは重複除去の処理を加えているのが原因です。
16分音符や装飾音が抜けているのをみると、早いパッセージは検出されにくいようです。
(生データを見るとこの部分も確信度が0.7未満になっているようでした)
以上を前提にあらためてヴァイオリンでの結果を見てみると、電子ピアノでの結果と同様に同音重複箇所と16分音符の箇所は音が抜けているようです。また、装飾音がついている元の音も抜けていました。加えてそれ以外で抜けている箇所を実際の演奏と聴き比べるとピッチが少しずれている箇所のようでした。
確信度を0.7から下げればもしかするとピッチがあっていないものだけが抜ける、という状態になるかもしれません。ただ、早いパッセージ・スタッカート・重音等弾き方はさまざまで、全ての状態で正しい結果が出るように調整するのは難しそうです。
おまけ : オタマトーン
ここで終わろうと思ったのですが、我が家にはもう一つ楽器がありました。
そう、可愛らしい見た目のこいつ。オタマトーンです。
ヴァイオリンと感覚は同じですが、正しい音程で弾くのはなかなか難しいことで有名なオタマトーンでも試してみたいと思います。
というわけで早速録音。
自分的にはなかなか上手くできたと思います。ちょっと自信あり。楽しみです。
さあ、実行してみましょう!
検出された音: []
正解: ['C4', 'D4', 'E4', 'F4', 'G4', 'A4', 'B4', 'C5']
1音目: 検出=なし 正解=C4 ❌
2音目: 検出=なし 正解=D4 ❌
3音目: 検出=なし 正解=E4 ❌
4音目: 検出=なし 正解=F4 ❌
5音目: 検出=なし 正解=G4 ❌
6音目: 検出=なし 正解=A4 ❌
7音目: 検出=なし 正解=B4 ❌
8音目: 検出=なし 正解=C5 ❌
正答率: 0/8 = 0.0%
な、なんだってー!!
検出すらされてない!嘘でしょ!?
とりあえず生データを確認します。
開始時間 終了時間 MIDI 音名 確信度
---------------------------------------------
10.58 10.99 72.0 C5 0.684
8.31 8.92 68.0 G#4 0.620
8.29 8.94 80.0 G#5 0.609
7.21 7.59 78.0 F#5 0.337
7.21 7.89 66.0 F#4 0.689
6.04 6.70 64.0 E4 0.522
4.94 5.65 63.0 D#4 0.611
4.90 5.16 82.0 A#5 0.317
2.47 3.22 59.0 B3 0.480
2.46 2.83 83.0 B5 0.311
0.72 0.92 32.0 G#1 0.466
0.66 0.86 44.0 G#2 0.286
0.56 0.74 37.0 C#2 0.341
9.47 10.13 70.0 A#4 0.638
10.99 11.87 71.0 B4 0.580
9.66 10.11 82.0 A#5 0.465
0.99 1.18 44.0 G#2 0.424
3.82 4.40 61.0 C#4 0.356
3.80 4.38 95.0 B6 0.408
6.06 6.62 98.0 D7 0.390
9.73 10.12 89.0 F6 0.339
0.01 0.20 29.0 F1 0.384
10.62 10.83 84.0 C6 0.386
2.92 3.09 93.0 A6 0.366
5.26 5.56 97.0 C#7 0.358
5.11 5.54 75.0 D#5 0.336
1.46 1.61 45.0 A2 0.332
確信度が低い上にいろんな音が検出されています。
MIDI変換されたものがどうなったのかも気になりますね...。
見てみましょう。
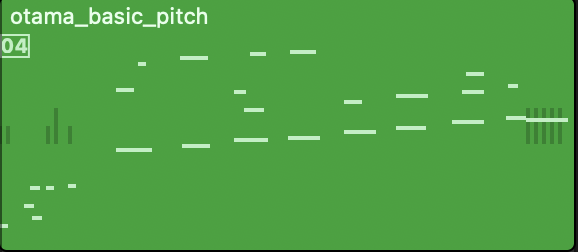
複数の音が同時に鳴っているようです。再生してみたところ、一応ベースとしては音階になっていました。
うーん。オタマトーン。なかなか難解なやつです。
まとめ
今回はBasic PitchというAIモデルを使用しピッチの検出をしてみました。
当初の目標としては、実際の曲でピッチがあっている/あっていないの判定ができれば、と思っていたのですが、それはなかなか難しそうでした。
ピッチのズレを細かく数値化したい場合はBasic Pitchではなく、librosaのような従来手法の方が向いていそうです。AIを使っているからと飛びつくのではなく、何をしたいかで技術を使い分ける必要があるかと思います。
ただ、生演奏を録音し、MIDIに変換するという使い方ではなかなか使えそうで面白かったです(これがオーケストラ楽曲になるとどうなってしまうのだろう、という一抹の不安と多大なる興味はありますが)。
今後AIが発達し、楽譜を読み込み演奏を聴かせるだけでリアルタイムでピッチ判定をし、間違った音符を楽譜上で赤くしてくれる等ができるようになると良いな、と思いました。
ますますの技術発展に期待しつつ、どうなっていくか楽しみです。
参考リンク
Author

その他おすすめ記事
FastAPI × Diffusers でローカル完結の「顔属性変換」学習アプリをつくる
生成 AI を「使う」だけでなく「アプリに組み込む」とどうなるのか。これを手を動かして理解したくて、人物写真をアップロードすると顔の属性(性別的な見た目)だけを別の性別に変換する学習用 Web アプリを個人で作りました。外部の画像生成 API には一切頼らず、推論まですべてローカルで完結させているのが特徴です。本記事では、その構成と実装上の判断、つまずいた点を技術寄りに整理して共有します。 なぜ「ローカル完結」にこだわったのか 顔写真は最もセンシティブな個人データのひとつです。学習目的とはいえ、自分や知人...

RAG: コンセプトから Bedrock + OpenSearch Serverless での構築まで
Large Language Model (LLM) は驚くべき汎用性を持っていますが、次の二つのケースでは決まって失敗します。学習時に見ていない情報を尋ねられたとき、そしてその情報が学習期間の締め切り日 (cut-off date) 以降に変化したときです。 ファインチューニング、つまりモデルを自分のデータでさらに学習させて自分のドメインの詳細を吸収させる手法は、この二つの失敗に対する一つの答えです。ただし、コストが高く、反復が遅く、根底のデータが変わった瞬間に古くなります。多くのチームにとって本当に欲...
