Large Language Model (LLM) は驚くべき汎用性を持っていますが、次の二つのケースでは決まって失敗します。学習時に見ていない情報を尋ねられたとき、そしてその情報が学習期間の締め切り日 (cut-off date) 以降に変化したときです。
ファインチューニング、つまりモデルを自分のデータでさらに学習させて自分のドメインの詳細を吸収させる手法は、この二つの失敗に対する一つの答えです。ただし、コストが高く、反復が遅く、根底のデータが変わった瞬間に古くなります。多くのチームにとって本当に欲しいのは、クエリ時にモデルに新鮮なプライベートコンテキストを与える方法です。それが Retrieval-Augmented Generation (RAG) のしていることです。
この記事では RAG を三つのレイヤーで説明します。まず、概念として、RAG とは何か、どんなときに有効かを整理します。次に、プロトタイプが実際のユーザーの活用に耐えられるかの実践プラクティス。最後に、Amazon Bedrock と Amazon OpenSearch Serverless を使った AWS 上でのハンズオン構築です。
RAG とは
考え方はシンプルです。ユーザーが質問をしたとき、まず自分が管理するコーパスから関連するドキュメントを少数 取得 (retrieve) し、それをコンテキストとしてプロンプトを 拡張 (augment) し、そのコンテキストに基づいて LLM が 生成 (generate) します。
これはモデルが学習した結果ではありません。答えがすでにコンテキストとして含まれた、より良いプロンプトを受け取っているだけです。
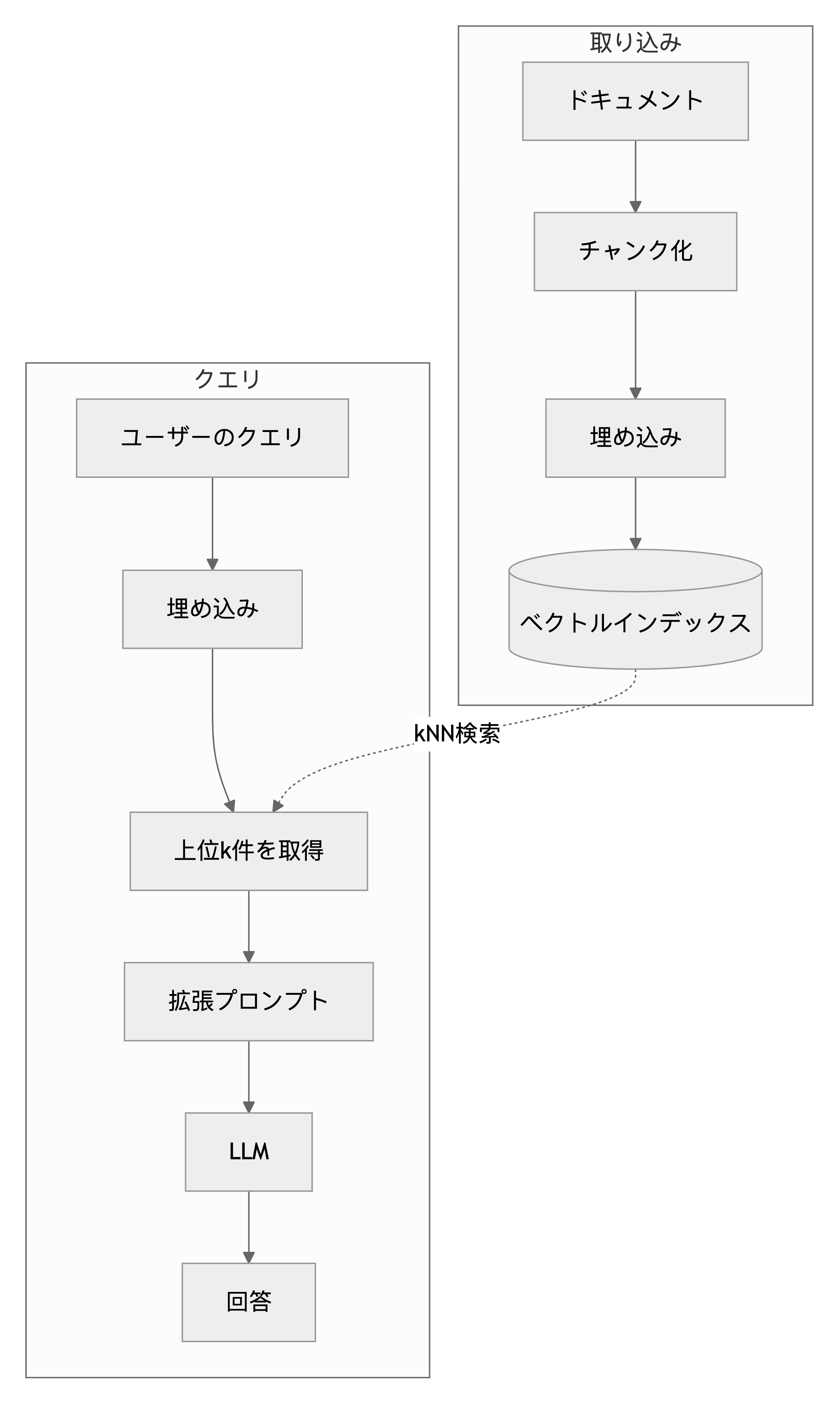
RAG パイプラインの構造
すべての RAG システムには二つのパスがあります。
取り込みパス (Ingestion path) はオフラインで、コーパスが変わったときに実行されます:
- ドキュメントを LLM のコンテキストウィンドウに快適に収まる程度の小さなパッセージに チャンク化 (chunk) する。
- 埋め込みモデルを使って各チャンクをベクトルに 埋め込む (embed)。
- 近似最近傍探索をサポートするストアにベクトルを インデックス化 (index) する。
クエリパス (Query path) はユーザーリクエストごとに実行されます:
- 同じ埋め込みモデルでユーザーの質問を 埋め込む。
- ベクトルインデックスから類似度の高い上位 k 件のチャンクを 取得する。
- 取得したチャンクをプロンプトのコンテキストとして渡し、回答を 生成する。
RAG とファインチューニング
| ユースケース | 適している方 | 理由 |
|---|---|---|
| プライベートまたはドメイン特化文書の Q&A | RAG | クエリ時に事実を取得するので、回答が常に新鮮で出典付きにできる。 |
| 一貫したトーン、スタイル、フォーマット | ファインチューニング | モデルが直接その振る舞いを学習する。 |
| 頻繁に更新されるサポートナレッジベース | RAG | 再インデックス化は再学習よりも簡単。 |
| 専門ドメインの執筆 | 両方使うことが多い | RAG が事実を供給し、ファインチューニングが言い回しや慣習を補う。 |
| 厳格な出力スキーマ | ファインチューニングまたは構造化プロンプティング | 知識の取得よりも振る舞いの制御が重要。 |
RAG とファインチューニングは相互排他的ではなく、多くの本番システムは両方を使います。振る舞いはファインチューニングし、知識は取得しましょう。
ベストプラクティス
以下の実践は、最も重要なベストプラクティスの一部です。中でも、検索品質が最も効果的な改善ポイントです。
-
構造を意識したチャンク化と豊富なメタデータでクリーンに取り込む。 チャンク化の前にテキスト抽出を正しく行うこと: PDF はテキストレイヤーを読み込むため、スキャン文書には OCR フォールバックが、スプレッドシートや HTML にはフォーマット固有のパーサーが必要です。境界を意識した分割 (まずページ区切り、次に段落、最後に文) を優先し、構造がないときだけ固定サイズにフォールバックします。500 トークン、50 トークンのオーバーラップは出発点として妥当ですが、ドキュメントタイプごとに調整してください。FAQ やサポートコンテンツには小さなチャンク、密度の高い技術文書や法務文書には大きなチャンクを。各チャンクにメタデータ (ソース URL、セクション、ページ、最終更新日) を常に保持して、フィルタリングや引用を可能にします。
-
インデックスごとに埋め込みモデルとバージョンを固定する。 埋め込みモデルは各チャンクを固定サイズの浮動小数点数ベクトルにマッピングします。次元 (dimension) はそのベクトルの長さです (Titan v2 は 1024 次元を出力します)。埋め込み空間は互換性がないので、モデルを変えるとコーパス全体を再インデックス化する必要があります。インデックスにモデル名、バージョン、次元をメタデータとしてタグ付けし、クエリ時の埋め込みと食い違わないようにします。モデルの入力上限を尊重してください: 長いチャンクは事前に分割しないと黙って切り詰められます。
-
ハイブリッド検索、リランキング、調整された kNN インデックスで取得する。 ベクトル検索だけでは弱点があります: 固有名詞、完全一致フレーズ、レアな用語に弱いです。ベクトル類似度と BM25 キーワードスコアを組み合わせて ハイブリッド検索 を行います。top-k はクエリタイプごとに調整するパラメータで、定数ではありません。リランカー (Cohere Rerank のようなクロスエンコーダー、または自分でファインチューニングしたもの) を上位 20〜50 件の候補に適用し、リランク後の上位 3〜5 件を保持します。kNN インデックス自体にも調整すべきパラメータがあります: HNSW の
m(グラフの接続性、デフォルト 16)、ef_construction(構築時の精度、通常 256〜512)、ef_search(クエリ時の精度とレイテンシのトレードオフ)。埋め込みモデルのドキュメントで指定された類似度メトリックに従ってください (正規化された埋め込みにはcosinesimilが一般的ですが、モデルによっては内積や L2 を指定します)。 -
レスポンスパスに、拒否、引用、検証を設計する。 検索が関連するものを返さなかった場合に何が起きるか、明示的に決めてください: モデルは適当に作るのではなく、拒否すべきです。コンテキストチャンクに番号を振り、モデルに引用するよう指示します: 「コンテキストのみを使って答えてください。出典は [1]、[2] のように引用してください。」厳格な出力スキーマには、プロンプトのヒューリスティックやファインチューニングよりも、モデルの function-calling や構造化出力 API を優先し、プログラム的な動作を駆動するものには下流のバリデーターと組み合わせてください。取得したテキストはサニタイズしてください: プロンプトインジェクションを運んでくる可能性があるので、制御トークンを除去し、インデックスされたコンテンツと出力の両方から PII をフィルタリングします。
-
評価、予算管理、運用。 測れないものは改善できません。ゴールデンセット (50〜200 件の質問と回答のペア) を初日に作成し、二つの指標を別々に計測します: 検索の recall@k (正しいチャンクが上位 k 件に入っているか) と 生成の忠実度 (faithfulness) (回答が取得したコンテキストのみに基づいているか)。RAG は従量課金です。10 万チャンクを 100 万トークンあたり $0.10 で埋め込むのが一つのコスト、生成にフロンティアモデルを使うのがもう一つのコストです。各ステージにレイテンシ予算を設定し (embed: <100ms、retrieve: <50ms、generate: <2s)、それぞれを計測します。インデックスがどれくらい新鮮である必要があるかを決めてください。書き込み時の差分アップサートは夜間の完全再インデックス化よりもシンプルですが、より多くの実装が必要です。
AWS 上での構築
Amazon Bedrock を埋め込みと生成に、Amazon OpenSearch Serverless をベクトル検索に使った AWS 上での最小限のエンドツーエンド RAG サービスを見ていきましょう。
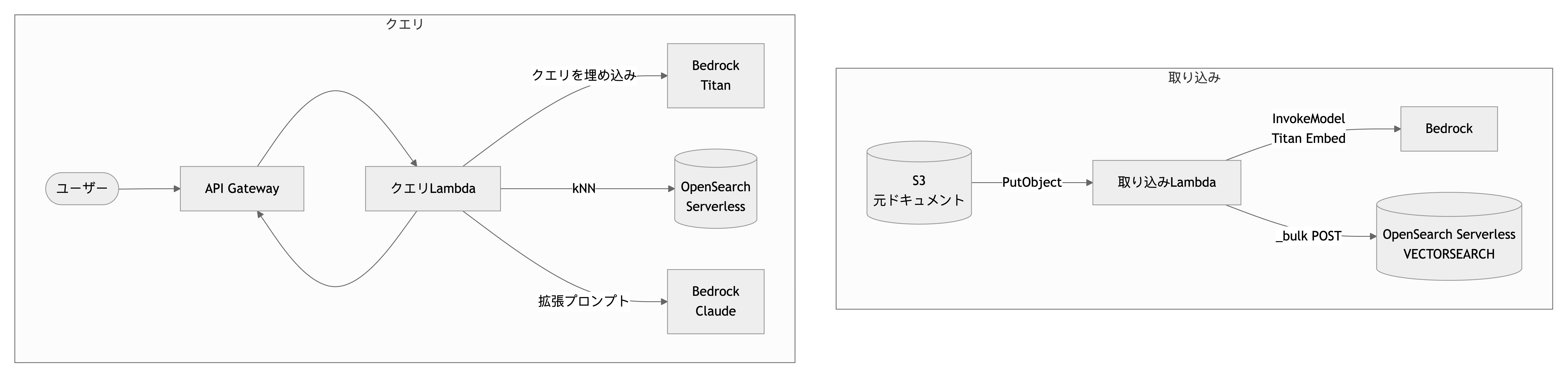
コンポーネント:
- S3: 元ドキュメントが配置される場所。
- 取り込み Lambda: S3 PutObject でトリガーされ、チャンク化し、Bedrock 経由で埋め込み、OpenSearch にインデックス化します。
- OpenSearch Serverless:
VECTORSEARCHタイプのベクトルコレクション。 - API Gateway + クエリ Lambda: 公開クエリエンドポイント。質問を埋め込み、kNN を実行し、拡張プロンプトで Bedrock を呼び出します。
- Bedrock: 埋め込みには
amazon.titan-embed-text-v2:0、生成にはanthropic.claude-3-5-sonnet。
OpenSearch Serverless (Terraform)
resource "aws_opensearchserverless_security_policy" "encryption" {
name = "${var.app.prefix}-rag-enc"
type = "encryption"
policy = jsonencode({
Rules = [{
Resource = ["collection/${var.app.prefix}-rag"]
ResourceType = "collection"
}]
AWSOwnedKey = true
})
}
resource "aws_opensearchserverless_collection" "rag" {
name = "${var.app.prefix}-rag"
type = "VECTORSEARCH"
depends_on = [aws_opensearchserverless_security_policy.encryption]
}
ネットワークおよびデータアクセスポリシーも同じパターンに従います。コレクションは、Lambda が SigV4 で認証する HTTPS エンドポイントを公開します。
取り込み Lambda (Go)
func handler(ctx context.Context, evt events.S3Event) error {
for _, rec := range evt.Records {
body, err := s3Get(ctx, rec.S3.Bucket.Name, rec.S3.Object.Key)
if err != nil {
return fmt.Errorf("s3 get: %w", err)
}
chunks := chunkText(string(body), 500, 50)
vecs, err := embedAll(ctx, chunks, 8)
if err != nil {
return fmt.Errorf("embed: %w", err)
}
if err := aossBulkIndex(ctx, rec.S3.Object.Key, chunks, vecs); err != nil {
return fmt.Errorf("index: %w", err)
}
}
return nil
}
embedAll は bedrock:InvokeModel の呼び出しを境界のあるワーカープールで並列実行し、チャンク順にベクトルを返します。aossBulkIndex は全チャンクとベクトルのペアを含む 1 回の SigV4 署名済み POST /_bulk を発行します。インデックスされる各ドキュメントは {"text": chunk, "embedding": vec, "source": key} の形をしています。
クエリ Lambda (Go)
func handler(ctx context.Context, req events.APIGatewayProxyRequest) (*events.APIGatewayProxyResponse, error) {
var body struct {
Question string `json:"question"`
}
if err := json.Unmarshal([]byte(req.Body), &body); err != nil {
return utils.BadRequest("invalid json"), nil
}
qvec, err := bedrockEmbed(ctx, body.Question)
if err != nil {
return nil, fmt.Errorf("embed query: %w", err)
}
chunks, err := aossKNN(ctx, qvec, 5)
if err != nil {
return nil, fmt.Errorf("retrieve: %w", err)
}
prompt := buildPrompt(body.Question, chunks)
answer, err := bedrockGenerate(ctx, prompt)
if err != nil {
return nil, fmt.Errorf("generate: %w", err)
}
return utils.SuccessResponse(200, map[string]any{
"answer": answer,
"sources": chunkSources(chunks),
}), nil
}
buildPrompt は取得したチャンクに番号を振り、Claude に引用するよう指示します。aossKNN は embedding フィールドに対して OpenSearch の knn クエリを実行します。
推奨される次のステップ
- リランキングを追加する。
aossKNNとbuildPromptの間にクロスエンコーダーの呼び出しを差し込みます。 - ハイブリッド検索を追加する。 OpenSearch はネイティブにサポートしています:
knnクエリとmatch句を組み合わせ、重みを調整します。 - 評価を追加する。 正解がわかっているテスト質問のセットを少数保持し、変更のたびに再実行することで、検索と回答が良くなっているか悪くなっているかを判断できます。
まとめ
RAG は応用 LLM の中でも最もレバレッジの効くパターンの一つです。始めるのは簡単ですが、スケールでうまく機能させるのは難しい。コンセプトはシンプルで、ベストプラクティスが本番で生きるところで、上記の AWS 構築はゴールではなくスタートラインです。
これを土台にして構築するなら、それぞれ独立した記事に値する二つのフォローアップは 評価 (evaluation) (検索が実際によくなっているか知る方法) と リランキング (reranking) (ハイブリッド検索の次に最大の精度レバー) です。この二つの領域が、RAG システムがデモのままで終わるか、本番で信頼できるものになるかの大部分を決定します。
参考文献
Author

その他おすすめ記事
AI-DLC実践ガイド: AWS提唱のAI駆動開発ライフサイクルを現場で回す【実測データ公開】
AI-DLC(AI-Driven Development Lifecycle)とは、AWS が 2025 年に提唱した、AI エージェントを前提に開発ライフサイクル全体を再設計する方法論です。「AI にコードを書かせる」の一歩先、つまりチケットの粒度・品質ゲート・計測までをまるごと AI 前提に作り替えます。 日本でも Developers Summit 2026 Summer のセッションなどで注目が集まっていますが、公開されている情報の多くは概念紹介にとどまっています。本記事では、Monstarlab...

FastAPI × Diffusers でローカル完結の「顔属性変換」学習アプリをつくる
生成 AI を「使う」だけでなく「アプリに組み込む」とどうなるのか。これを手を動かして理解したくて、人物写真をアップロードすると顔の属性(性別的な見た目)だけを別の性別に変換する学習用 Web アプリを個人で作りました。外部の画像生成 API には一切頼らず、推論まですべてローカルで完結させているのが特徴です。本記事では、その構成と実装上の判断、つまずいた点を技術寄りに整理して共有します。 なぜ「ローカル完結」にこだわったのか 顔写真は最もセンシティブな個人データのひとつです。学習目的とはいえ、自分や知人...
