いつの間にか、誰も議事録を書かなくなっていました。
Google Meet で Gemini が自動的に文字起こしをして、会議が終わると要約とアクションアイテムを出してくれます。気づいたら、チームの誰もがそれを当たり前のように使っていました。それを読むかどうかは人それぞれです。ただ、『会議で話したことが5分後に要約されたテキストになる』という事実は、最初に見たとき素直に驚きました。
この変化は、働き方の大きな移行の入り口だったと思います。私はこの新たな働き方を、「リモートAIワーク」と定義しました。 この記事では、リモートAIワークについて、これまでのリモートワークとの違いや実戦のポイントなどについて、私が感じたことを紹介します。
リモートAIワークという考え方
リモートAIワークは、AIがリモートで人間を少しだけ助けてくれる、という話ではありません。実行そのものがリモートになる働き方の変化のことです。
従来のリモートワークでは、「どこで働くか」が変わりました。人がオフィスから分散し、自宅やカフェで仕事をするようになりました。一方で、実行の主体はあくまで人間のままでした。
リモートAIワークでは、「誰がどこで実行するか」が変わります。仕様やゴールを決めるのは人間ですが、その仕様に沿った探索・実行・再試行は、リポジトリや環境に接続されたAIエージェントが非同期に進めます。人間は意図をガイドし、境界を定義し、最終的に承認する役割にシフトし、AIが探索し、実行し、提案する役割を担います。
たとえば、これまで開発者がやっていた「Issueを読み、コードを変更し、テストを回し、PRを作る」という一連の作業を、エージェントがリモートで実行し、人間は「Issueの定義」と「結果のレビュー」に集中するような状態です。実装の“手”そのものが、自分のPCの前から離れていくイメージに近いかもしれません。
これは単なるツール活用や生産性向上テクニックの話ではありません。どこで人間同士の調整が発生し、誰が実行し、どこで検証されるのか——仕事の構造そのものが変わる話なのです。この違いを、まずは人だけが分散したリモートワークの限界から見ていきます。
リモートワークが解決しなかった問題
パンデミック以降、私たちは「場所を選ばずに働ける」ことを手に入れました。それは本当の変化でした。
しかし、リモートワークが成熟するにつれて、実際に仕事をする時間より、仕事を調整する時間のほうが増えているという別の問題が浮かび上がってきました。
少し前までの開発ワークフローを正直に書き出すとこんな流れでしょうか。
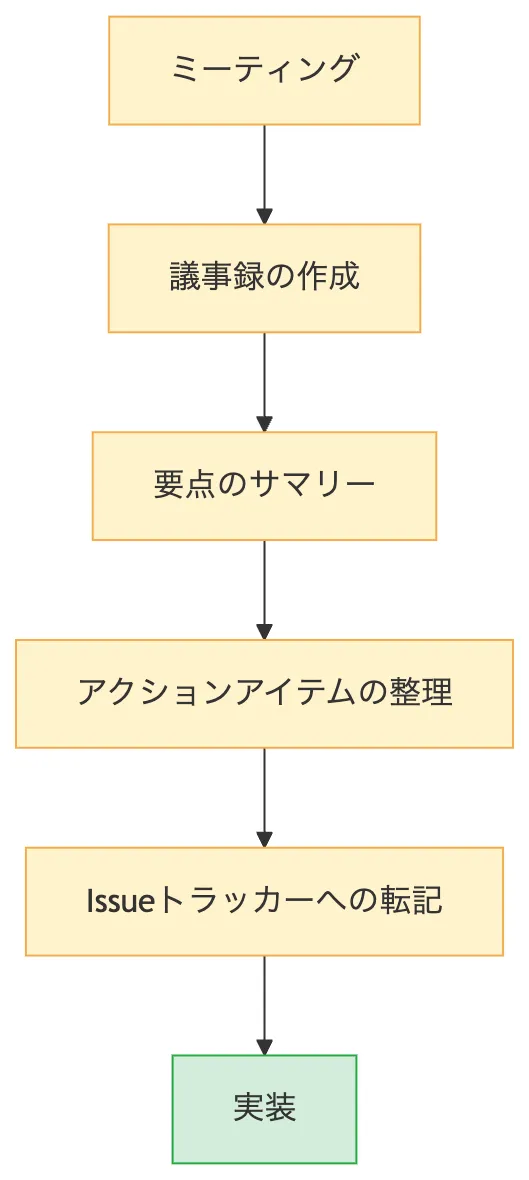
Microsoft の Work Trend Index によれば、リモートワーク移行後、ミーティング時間は2倍以上に増加し、チャットトラフィックは約45%増加しました。
The average Teams user is sending 45 percent more chats per week and 42 percent more chats per person after hours, with chats per week still on the rise. (Microsoft, Work Trend Index)
(翻訳:平均的なTeamsユーザーの1週間のチャット送信数は45%増加し、営業時間外の1人あたりのチャット数も42%増加しており、週あたりのチャット数は現在も増加傾向にある。)
リモートワークは場所の制約を取り除きました。しかし調整コストは何も変わらなかったのです。
理由はシンプルです。人間が実行者である限り、仕事は人間同士の調整を必要とします。
言い換えれば、調整コストの根本原因は「人間が実行者であること」です。どれだけ速く働いても、そこは変わりません。実行そのものを人間から切り離したとき、はじめて調整の必要性が減るのです。
そして AI エージェントの登場によって、実行を人間から切り離すという選択肢が、初めて現実味を帯びてきました。
AIの進化:アシストからエージェントへ

ソフトウェア開発における最初の AI 活用は、比較的シンプルなものでした。GitHub Copilot に代表されるコーディングアシスタントは、開発プロセスの各ステップの速度を大きく向上させました。
実証研究では、AIアシスタントを使った開発者は、そうでない開発者と比べてタスクを最大55%速く完了したことが示されています。
The performance difference between treated and control groups are statistically and practically significant: the treated group completed the task 55.8% faster (95% confidence interval: 21-89%). (Peng et al., 2023)
(翻訳:介入群と対照群のパフォーマンスの差は統計的にも実用的にも有意であった。介入群は対照群よりも55.8%早くタスクを完了した(95%信頼区間:21-89%))
しかし、この段階で変わるのはステップの速度だけです。 開発のワークフローそのものは変わりません。
開発者は依然として、
- 要件を考え
- 設計し
- 実装し
- テストする
という一連のプロセスを進めます。 AIはその各ステップを補助しますが、実行の主体は人間のままです。
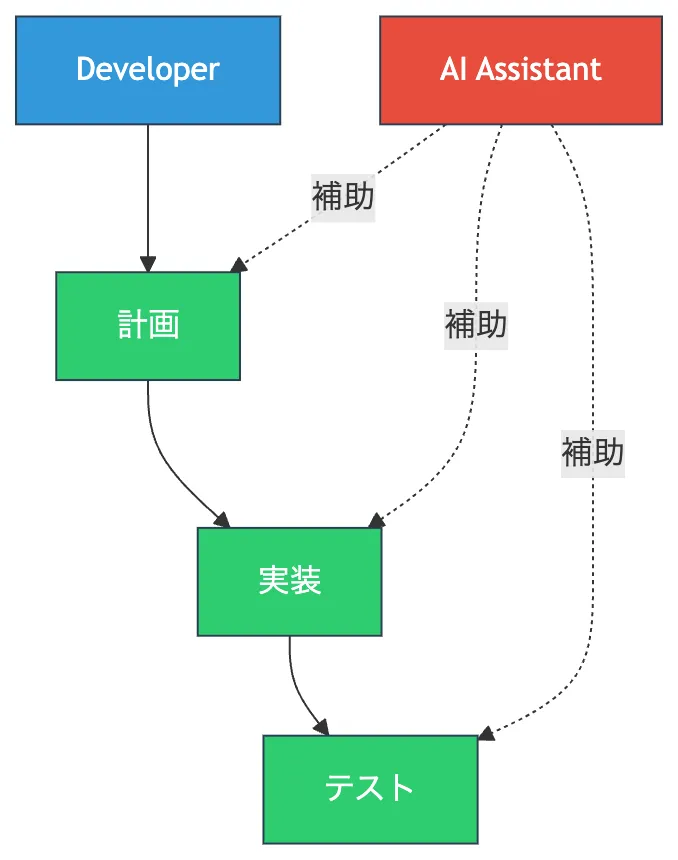
次の変化は、AIが「回答する存在」から「ループの中で動く存在」へ変わったことです。
アシスタントはプロンプトに応答します。 一方、エージェントは目標を与えられると、自律的なループの中でタスクを進めます。
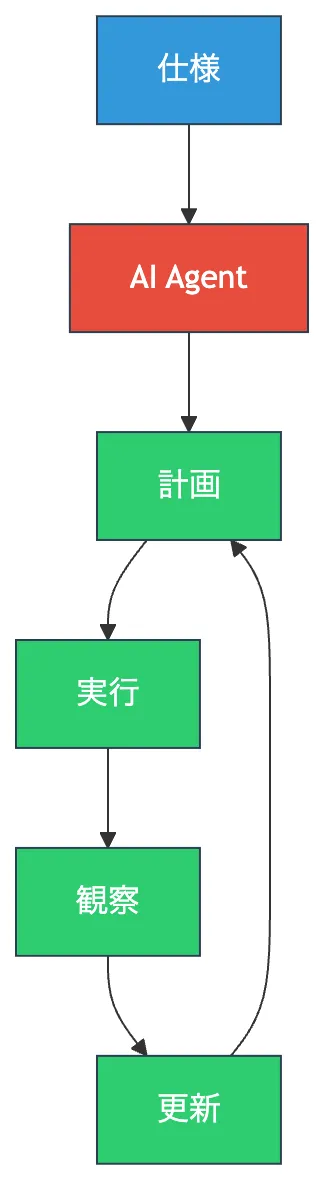
このループは、AI研究では ReAct(Reasoning + Acting)や Reflexion といったアーキテクチャとして定式化されています。 単発の応答ではなく、環境からのフィードバックを受け取りながら行動を更新し続ける仕組みです。
ReAct prompts LLMs to generate both verbal reasoning traces and actions pertaining to a task in an interleaved manner, which allows the model to perform dynamic reasoning to create, maintain, and adjust high-level plans for acting... (Yao et al. (2022) / ReAct)
(翻訳:ReActはLLMに言語的な推論の軌跡とタスク関連の行動を交互に生成させる。これにより、モデルは動的な推論を行って行動のための高次計画を作成、維持、調整できる...)
Reflexion converts binary or scalar feedback from the environment into verbal feedback in the form of a textual summary, which is then added as additional context for the LLM agent in the next episode. This self-reflective feedback acts as a 'semantic' gradient signal by providing the agent with a concrete direction to improve upon... (Shinn et al. (2023) / Reflexion)
(翻訳:Reflexionは、環境からの二値またはスカラーのフィードバックをテキスト要約の形による言語的フィードバックに変換し、次のエピソードのLLMエージェントの追加コンテキストとして追加する。この自己反省的フィードバックは「意味的」な勾配シグナルとして機能し、エージェントに改善のための具体的な方向性を提供する...)
重要なのは、このループによって人間の細かな調整を介さずにタスクが連続して実行される点です。
SWE-bench というベンチマークでは、言語モデルが実際の GitHub Issue を読み、
- コードを探索
- パッチを生成
- テストを実行
という一連の作業を、人間の介在なしに解決できることが示されています。
Rather than merely having to produce a short code snippet, our benchmark challenges models to generate revisions in multiple locations of a large codebase. (Jimenez et al., 2024 / SWE-bench)
(翻訳:単に短いコードスニペットを生成するのではなく、我々のベンチマークは、大規模なコードベースの複数箇所にわたる修正を生成することをモデルに要求する。)
つまり変わったのは、単なるツールの能力ではありません。 実行モデルそのものです。 AIは、人間の作業を速くする補助ツールから、タスクをループの中で実行する主体へと変わりつつあります。
実際の開発ワークフローに置き換えると、次のようなパイプラインになっているのは皆さんも体感していると思います。
- 人が GitHub Issue を確認する
- エージェントがコードを読み込みする
- Issue 内容を解決するためのコードを生成する
- テストを実行する
- CI が検証する
- Draft PR を作成する
- 人がレビューする
このパイプラインの中で、人間が関与するのは最初と最後だけです。
人間がやることは、タスクを定義し、結果をレビューすること。 実装の大部分はエージェントが進めます。
実行モデルは、静かに書き換わりました。
働き方の前提も変わる
実行そのものが人間から切り離されると、働き方の前提も変わります。これまでの開発では、実行主体が人間だったため、常に調整が必要でした。
- 誰が実装するのか
- どこまで進んでいるのか
- 次に何をするべきか
しかしエージェントがタスクをループの中で実行できる場合、この調整の多くは不要になります。人間は細かい作業の実行者ではなく、目標を与え、結果をレビューする存在になります。
すると重要なのは、「誰がどこで作業しているか」ではなくなり、どのエージェントがどのタスクを実行しているかが中心になります。
この前提の変化が、新しい働き方を生み始めています。
それがリモートAIワークです。
リモートAIワークが成立する3つの条件
AIがエージェントとして動けるようになっただけでは、リモートAIワークは成立しません。実際に運用してみると、いくつかの条件が必要になります。
条件1:AIが読めるコードベース
エージェントの精度は、コードの書き方よりリポジトリの状態に依存します。
AIが迷わず動けるリポジトリには共通した特徴があります。
- ディレクトリ構造が一貫している
- 命名規則が明確
- テストが整備されている
つまり「人間が読みやすいコード」と「AIが動きやすいリポジトリ」はほぼ同じものです。
ここでよくある疑問があります。
CLAUDE.md を書けば解決するのでしょうか?
最近の研究(Gloaguen et al., 2026)では少し違う結果が出ています。AIが自動生成した CLAUDE.md は成功率を下げ、推論コストを20%以上増加させました。
人間が書いた詳細版でもコストは増えます。最も効率が良かったのは、最小限の必須情報だけを書いたものでした。
Across multiple coding agents and LLMs, we find that context files tend to reduce task success rates compared to providing no repository context, while also increasing inference cost by over 20%. [...] human-written context files should describe only minimal requirements. (Gloaguen et al., 2026)
(翻訳)複数のコーディングエージェントやLLMにおいて、コンテキストファイルはリポジトリのコンテキスト(前提情報)を提供しない場合と比べてタスク成功率を低下させる傾向があり、同時に推論コストを20%以上増加させることがわかった。[...] 人間が書いたコンテキストファイルは、最小限の要件のみを記述するべきである。
コンテキストが増えるほど、AIはその指示を律儀に守ろうとして探索範囲が広がり、不要なステップが増えてしまいます。
重要なのは、何を書くかより、何を書かないかです。
# CLAUDE.md(最小限の例)
## ビルドとテスト
- テスト実行: `npm test`
- Linter: `npm run lint`(PRの前に必ず実行)
## 注意
- `src/legacy/` は変更しない
- DBマイグレーションは必ず手動レビューを通す
コードベースの概要やディレクトリ構造を書く必要はありません。 AIはコードを読んで理解できます。必要なのは、コードを読んでも分からない制約だけです。
条件2:自動化された検証とレビュー
AIの出力を盲目的に信頼することはできません。 だからこそ、検証とレビューの仕組みが不可欠です。
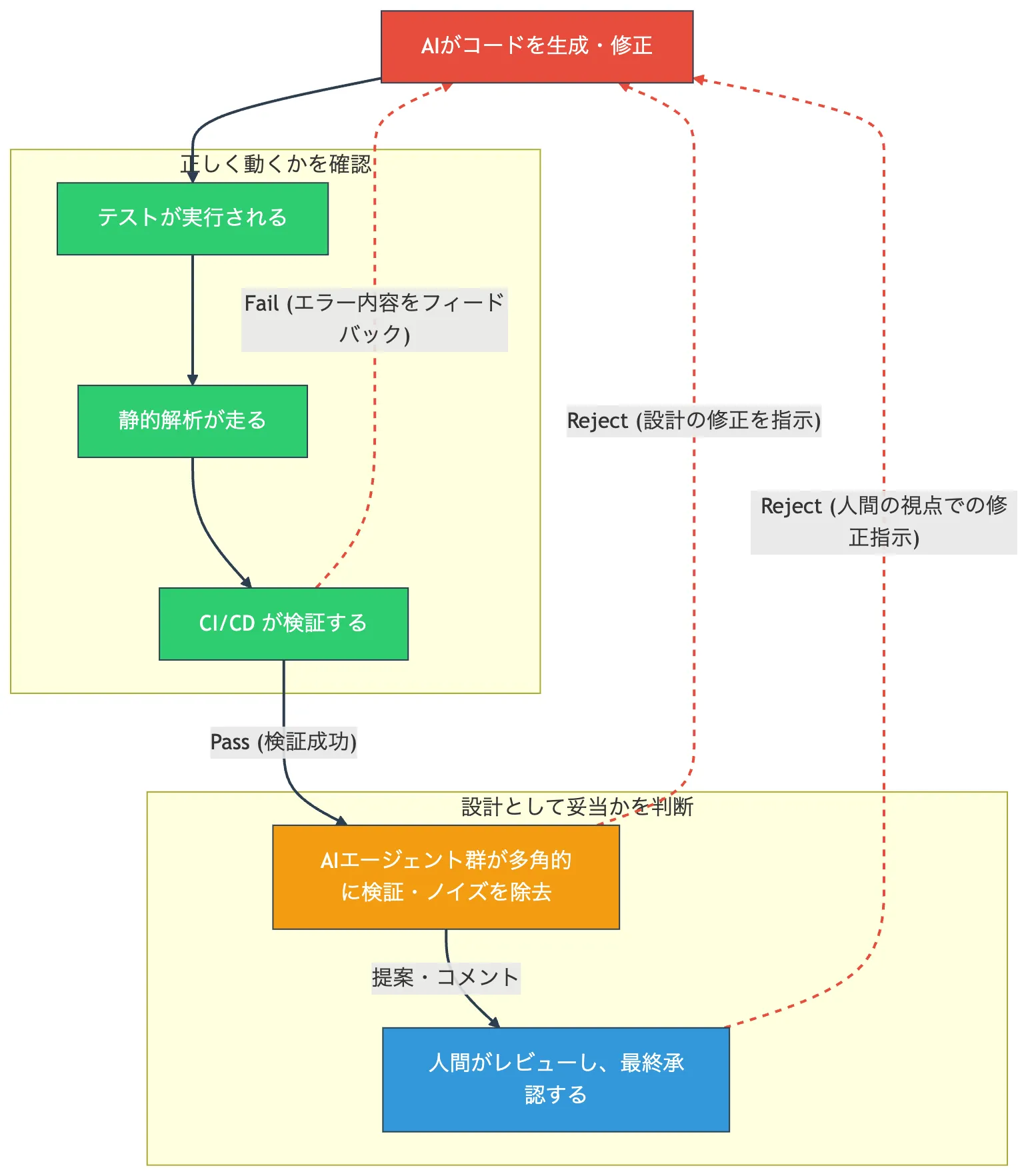
継続的インテグレーションと自動テストは、もともと人間のミスを防ぐために作られました。しかしこれは同時に、AIへの委譲を安全にするガードレールでもあります。一度テストやCIで弾かれたとしても、エラーログというフィードバックを返すことでAIは自らコードを修正し、再提出します。
テストが「正しく動くか」を確認するものだとすれば、レビューは「設計として妥当か」を判断するものです。
AIに実装を委ねるほど、このレビュー層の重要性は高くなります。しかし、単一のAIにレビューをさせると、もっともらしいが的外れな指摘(ノイズ)が増え、かえって人間の確認コストが跳ね上がるという問題がありました。
ここで有効なのが、Claude Code Review のようなマルチエージェントによる検証です。複数の特化型エージェントを走らせてバグ候補を実際のコードと照らし合わせることで、誤検知(False Positives)を自動でフィルタリングします。
https://code.claude.com/docs/en/code-review
さらに REVIEW.md を用いて「OAuthのエラーは必ずハンドリングする」「関数名はcamelCase」といったプロジェクト固有のルールを定義しておけば、人間が口酸っぱく指摘していたコンプライアンスチェックをAIに委譲できます。
重要なのは、AIはPRを勝手に承認(Approve)したりブロック(Block)したりしないという点です。AIはあくまで高度な「提案者・検証者」としてインラインコメントを残すにとどめ、最終的な意思決定(Approve)は人間が行います。
既存のワークフローを壊さずにAIを組み込むこと。これがリモートAIワークを安全に運用する最大の秘訣です。
条件3:非同期・分散実行
最後の条件が、リモートAIワークを文字通り「リモート」にします。
Claude Code の /loop を使うと、セッションが生きている間、エージェントが定期的にタスクを実行し続けます。
https://code.claude.com/docs/en/scheduled-tasks
$ /loop 30m 本番のエラーログを確認して、新しいエラーがあればサマリーを出して
⏺ CronCreate(*/30 * * * *: 本番のエラーログを確認して、新しいエラーがあればサマリーを…)
⎿ Scheduled xxxxxxxx (Every 30 minutes)
⏺ Scheduled:
- Prompt: 本番のエラーログを確認して、新しいエラーがあればサマリーを出して
- Cron: */30 * * * * (every 30 minutes)
- Recurring: yes (auto-expires after 3 days)
- Job ID: xxxxxxxx
Cancel anytime with CronDelete using job ID xxxxxxxx.
「自分がポーリングしていたもの」をAIに委譲する感覚です。
さらに Claude Code Remote Control を使うと、ローカルで動いているセッションをスマートフォンから操作できます。
https://code.claude.com/docs/en/remote-control
$ claude remote-control
·✔︎· Connected · xxxx · main
Single session · exits when complete
Continue coding in the Claude app or https://claude.ai/code/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx?bridge=xxxxxxxxxxxxxxxxxxxxxxxxxxx
space to show QR code
# QRコードが表示される → モバイルアプリでスキャン
自分がその場にいなくても、実行は続きます。
開発者の役割は変わるのか
3つの条件が揃ったとき、開発者の仕事の定義が変わっていく——少なくとも、私はそう予測しています。
| 時代 | エンジニアの役割 |
|---|---|
| 過去 | コードを書く人 |
| 現在 | AIとともにコードを書く人 |
| 近未来 | AIが実行できるシステムを設計する人 |
面白いのは、「AIが動けるシステム」を設計する能力が、「人間にとっても読みやすいシステム」を作る能力と重なっていることです。AIのためにリポジトリを整えたり、CLAUDE.md を最小限にすると、新メンバーのオンボーディングも速くなり、ドキュメントが実態と乖離しにくくなります。
AIが動けるシステムが完全に整備されて、エンジニアが不要になるという話ではありません。 むしろ逆で、何をAIに委譲できるかを判断し、AIが失敗したときに原因を特定できるエンジニアの重要性は上がると思っています。
おわりに
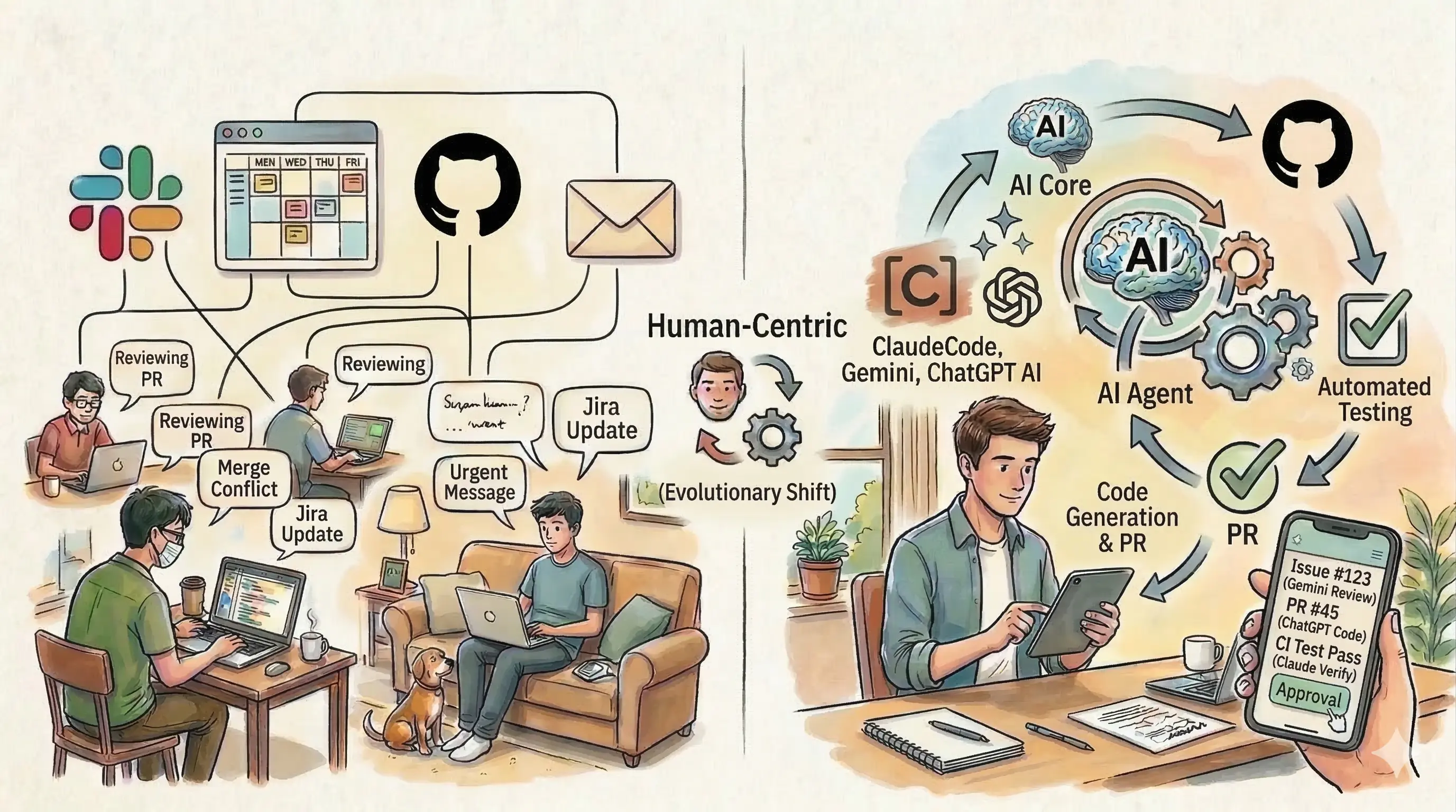
ここまで、リモートワークの調整コスト、エージェントアーキテクチャの進化、そしてリモートAIワークが成立するための条件について見てきました。
まだすべての開発がこの形になるわけではありません。 ただ、Issueを起点にエージェントが実装を進め、人がレビューするという流れは、すでに一部のプロジェクトで現実になり始めています。
それが新しい標準になるのか、それとも特定の領域に限られるのかは、まだ分かりません。
少なくとも言えるのは、これからの開発では「AIが実行できるシステムをどう設計するか」という問いが、少しずつ重要になってきているということです。
この変化がどこまで進むのかは、これからの現場の試行錯誤の中で見えてくるのだと思います。
参考文献
- Microsoft. Work Trend Index
- Yao et al. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv.
- Shinn et al. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv.
- Peng et al. (2023). The Impact of AI on Developer Productivity: Evidence from GitHub Copilot. arXiv.
- Jimenez et al. (2024). SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv.
- Gloaguen et al. (2026). Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents? arXiv.
Author

その他おすすめ記事
ゴールデンテスト - AI駆動開発における実践的なテストコードを考える
モンスターラボのエンジニアリングマネージャーの奥田です。 AIによりコードが大量に生成されるようになった今、ソフトウェアの品質担保はこれまで以上に重要なテーマとなりました。品質担保のためにテストコードを書くというのは多くの開発現場で行われていますし、テストコードも生成AIが書けるようになったことでテストカバレッジは大幅に向上していると思います。 一方で、大量に生成されたプロダクトコード、テストコードをチェックするのは大変な作業ですし、AIなどのツールを利用するにしてもガードレールとチェックポイントを適切に...

「ビジネスアナリストが仕様を書き、エンジニアが実装する」をAI時代に再設計する ── Spec Kitをオフショア開発にカスタマイズした話(設計編)
本記事では、github/spec-kit(以下、Spec Kit)をオフショア × AI駆動開発のプロジェクトに導入するにあたって、標準のSpec Kitに対してどんな設計判断を重ねてきたかを書き残します。本格運用はこれから始まります。だからこそ、判断のプロセスと、設計時点で見えている懸念を、後から検証可能な形で残しておきたいと考えました。 オフショア × AI駆動開発で感じている摩擦 ある一覧APIの仕様書には、「並び順に従って表示する」とだけ書いてあります。実装したエンジニアは、既存の同様のAPIに...
