みなさん、OpenSearch使ってますか?
聞き慣れない方は、もしかしたらElasticSearchのほうが聞き慣れていたりしますでしょうか?
OpenSearchは、Amazonが Elasticsearch のフォークを元に 2021 年に公開した検索エンジンで、Amazon OpenSearch Service はこれをマネージドサービスとして提供しています。
現在、AWS のマネージド検索サービスとしては OpenSearch のみが利用可能です。
今回は、このOpenSearchの説明および簡単な構築までやってみようと思います。
OpenSearchとは?
OpenSearchとは、取り込まれたデータの検索、視覚化、分析、などを行う検索・分析エンジンです。
Amazon OpenSearch Serviceは、このOpenSearchをマネージドサービスとして提供しており、スケーラビリティや可用性を確保しながら、セットアップし管理できるようになっています。
詳しい機能については、公式サイトをご確認ください。
メリット・デメリット
OpenSearchは、主に次のメリット・デメリットを持っています。 まず、メリットです。
| メリット | 説明 |
|---|---|
| スケーラビリティ | クラスタ内のノード数を増減させることで、容易にスケールアップ/スケールダウンが可能。 |
| パフォーマンス | フルテキスト検索や複雑なクエリに対して高いパフォーマンスを発揮。 |
| 強力な検索機能 | 構造化データと非構造化データの両方に対して強力な検索能力があります。 |
| 柔軟なデータモデリング | 様々なデータ形式に対応可能で、データのインデックス作成が容易。 |
次にデメリットです。
| デメリット | 説明 |
|---|---|
| コスト | OpenSearchの利用には、インスタンスタイプや数、ストレージ容量に応じてコストがかかります。 |
| 運用管理 | 完全なマネージドサービスであるものの、チューニングやスケーリングには一定の知識が必要となります。 |
OpenSearchを利用しないパターンとの比較
「OpenSearchを使っていきましょう!」という話の流れの中でいきなり「使わないほう」の話になりますが、 実際、サービスの規模によってはOpenSearchを利用する必要がないケースも多いかと思います。例えば下記の2パターンが挙げられます。
RDSへ直接クエリを発行するパターン
最も多いパターンではないでしょうか?
メリットとしては「シンプルであること」とリクエストに対してデータの整合性が取りやすいなどがありますが、
一方で、大量データの検索でのパフォーマンス低下や、DBまたぎ検索が難しい、複雑な全文検索やランキング、フィルタリング機能に限界があります。
もちろん、複雑なクエリを組むことで、ある程度実現することは可能ですが、その分メンテナンスコストの増加や実行スピードの遅延などが発生します。
RDS+ElastiCache(Memcached)を利用するパターン
こちらは、インメモリデータストアであるMemcachedに検索結果をキャッシュさせておくパターンです。 まだオンプレ主流だった頃によく使っていました・・・懐かしい(遠い目)
メリットとしては、パフォーマンス向上が比較的容易に実現できます。 RDS側の負荷が軽減されれば、RDSのコスト削減もできるかもしれません。 ただし、こう言ったキャッシュを利用する場合にはデータの整合性に注意する必要があり、 最新のデータを取得するためにはRDSとの整合性を保つ必要があります。
また、複雑な検索には向かないため、Memcached単体ではあくまでデータキャッシュにのみ使うべきでしょう。
結局何が言いたいかというと
複雑な検索や分析、大規模なデータや高トラフィックの処理が必要な場合は、OpenSearchを使うと良いよね!
OpenSearchの導入方法
言いたいことがうまくまとまった所で(?) ここからサクッとOpenSearchを構築していきましょう! なお、本手順はブログ用の簡易構築を目的としており、セキュリティに関して担保しておりません。 実際に本番運用するような場合には、その点も踏まえて正しく設計・構築する事を推奨します。 (参考)Amazon OpenSearch Service の開始方法
1. 前提の確認
OpenSearchを設定可能なAWSアカウントをご用意ください。
2.ドメインの作成
AWS OpenSearch Serviceの設定を行います。細かな設定を行うため、マネージド型クラスターを選択してドメインを作成します。
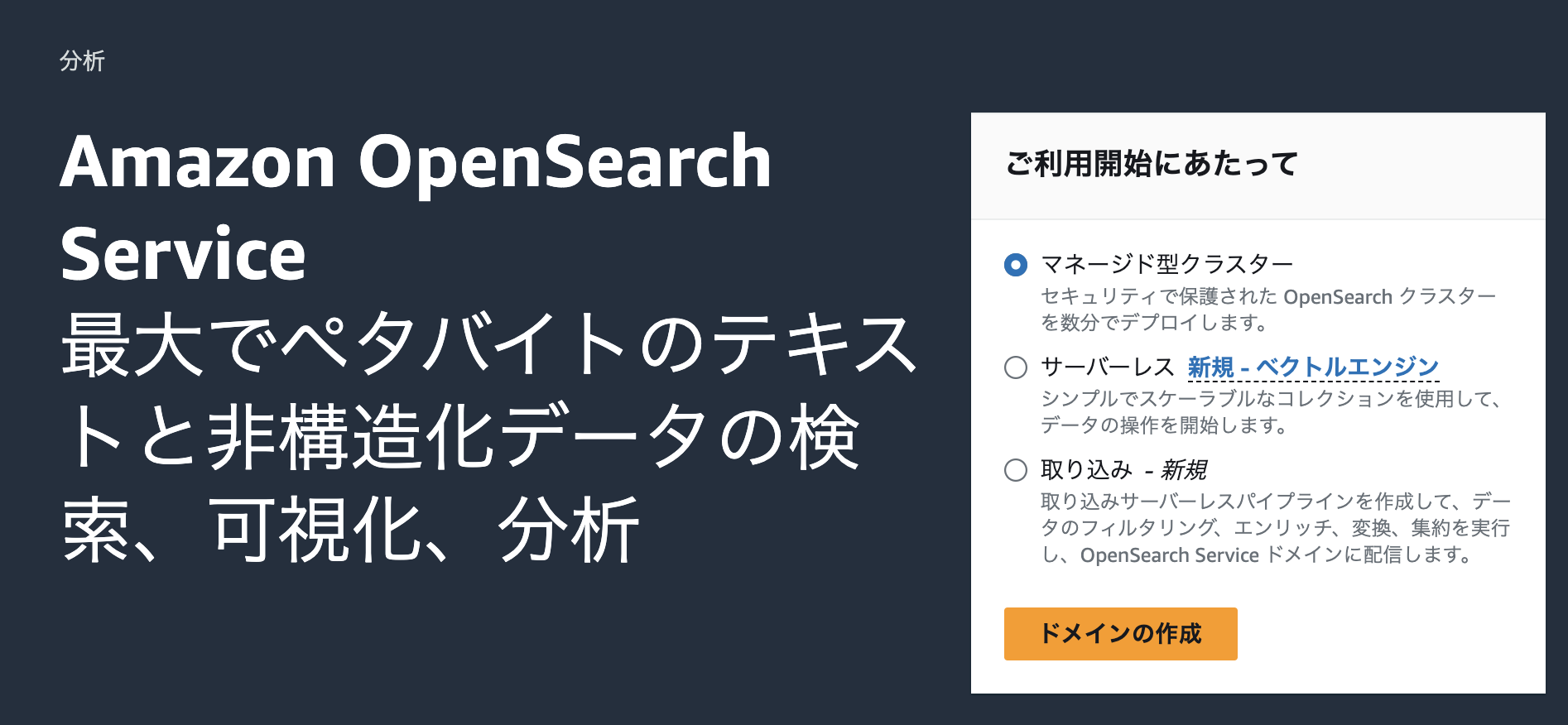
ドメインの各設定項目は次の表の通りです。設定値はサンプルであるため、環境を構築する目的や社内ルール/環境に応じて、適切な設定に変更してください。
| 設定カテゴリ | 設定項目 | 設定値 | 備考 |
|---|---|---|---|
| 名前 | |||
| ドメイン名 | sample-domain | お好きな名前に設定してください。 | |
| ドメイン作成方法 | |||
| ドメイン作成方法 | 標準作成 | 料金を抑えた小規模な構成とするためカスタマイズ可能な標準作成を選択します。 | |
| テンプレート | |||
| テンプレート | 開発 / テスト | ||
| デプロイオプション | |||
| デプロイオプション | スタンバイなしのドメイン | お試し用のテスト環境で可用性は重要ではないため、スタンバイは不要です。 | |
| アベイラビリティーゾーン | 1-AZ | コストを考慮し最小設定としています。 | |
| エンジンのオプション | |||
| バージョン | 2.19(最新) | 2025/09時点の最新バージョンを選択しています。 | |
| データノードの数 | |||
| インスタンスファミリー – 新規 | 汎用 | 複雑なクエリを効率的に処理するためにはメモリを優先するインスタンスがオススメですが、今回は試験環境のためt3.small.searchを選択可能なインスタンスを選択しています。 | |
| インスタンスタイプ | t3.small.search | テスト目的であるため、小さいものを選択しています。 | |
| データノードの数 | 1 | 本番運用においては必要に応じて増やしてください。 | |
| ストレージタイプ | EBS | ||
| EBS ボリュームタイプ | 汎用(SSD) - gp3 | ||
| ノードあたりの EBS ストレージサイズ | 10 | 最小値を設定しています。 | |
| 高度なボリュームタイプオプション→ノードあたりの合計IOPS | 3000 IOPS | 最小値を設定しています。負荷テスト等を実施する場合は、必要に応じて変更してください。 | |
| 高度なボリュームタイプオプション→ノードあたりの総スループット | 125 MiB/秒 | 最小値を設定しています。一度に大量のデータを処理する場合などは必要に応じて変更してください。 | |
| 専用コーディネーターノード – 新規 | |||
| 専用コーディネーターノードを有効にする | false | ||
| カスタムエンドポイント | |||
| カスタムエンドポイントを有効にする | false | ||
| ネットワーク | |||
| ネットワーク | VPCアクセス | ||
| IP アドレスタイプ – 新規 | デュアルスタックモード – 推奨 | ||
| VPC | vpc-xxxxxxxxxxxxxxxxx | お使いの環境に合わせてVPCを選択してください。 | |
| サブネット | subnet-xxxxxxxxxxxxxxxxx | お使いの環境に合わせてサブネットを選択してください。 | |
| セキュリティグループ | sg-xxxxxxxxxxxxxxxxx | お使いの環境に合わせてセキュリティグループを選択してください。 | |
| きめ細かなアクセスコントロール | |||
| マスターユーザー | マスターユーザーを作成 | 今回はマスターユーザーを作成します。 | |
| マスターユーザー名 | opensearch_master | お好きな名前に設定してください。 | |
| マスターパスワード | ******** | パスワードは8文字以上、大文字+小文字+数字+特殊文字を含んでいる必要があります。 | |
| マスターパスワードを確認 | |||
| OpenSearch ダッシュボード/Kibana 用の SAML 認証 | |||
| SAML 認証を有効にする | false | ||
| JWT 認証と承認 – 新規 | |||
| JWT 認証と承認を有効にする | false | ||
| Amazon Cognito 認証 | |||
| Amazon Cognito 認証を有効化 | false | ||
| IAM アイデンティティセンター (IDC) 認証 – 新規 | |||
| IAM アイデンティティセンターで認証された API アクセスを有効にする | false | ||
| Advanced features | |||
| 自然言語クエリ生成と Amazon Q Developer 機能を有効にします。 | true | デフォルトのままでOKです。 | |
| アクセスポリシー | |||
| ドメインアクセスポリシー | きめ細かなアクセスコントロールのみを使用してください | ||
| 暗号化 | |||
| AWS KMS キーを選択する | AWS 所有キーを使用する | ||
| オフピークウィンドウ | |||
| 開始時刻 (UTC) | 13:00 | 時刻はUTCであることに注意しましょう。 | |
| 終了時刻 (UTC) | 23:00 次の日 | 自動入力です。 | |
| 自動ソフトウェア更新 | |||
| 自動ソフトウェア更新を有効にする | false | ||
| タグ – オプション | 今回は設定しません。 | ||
| 高度なクラスター設定 – オプション | 今回は不要です。 |
3.データのアップロード及びインデックスの作成
OpenSearchでは、検索エンジンがデータを整理し高速に検索できるようにするためインデックスを作成します。 インデックスとは、データを組織化して格納する基本的な単位であり、インデックスの中に複数のドキュメント(アップロードされたデータ)を格納します。
まずは、データを用意しましょう! OpenSearchにデータを登録するには、JSON形式でデータを用意する必要があります。 なお、今回は弊社支援実績の一部をサンプルデータとして利用します。
| No. | Type | Title | Tag |
|---|---|---|---|
| 1 | 開発 | ブランドの再定義とコーポレートサイト・製品サイトなど6000ページ超の刷新を支援 | UXデザイン, UIデザイン, Web開発, 運用・保守 |
| 2 | 開発 | グローバル拠点への情報発信が可能な社内ポータルサイト | UXデザイン, UIデザイン, Web開発 |
| 3 | 事業戦略 | AR技術などのテクノロジーを活用することにより、顧客のデジタル体験を近代化 | XR, 戦略策定, サービス設計, UXデザイン, UIデザイン, アプリ開発 |
| 4 | 成長基盤構築 | 映像学習の先駆けとなったサービスに企画から参画し、 オンライン学習の普及に貢献 | 戦略策定, サービス設計, UXデザイン, アプリ開発, PoC支援 |
No.1をJSON形式にすると下記のようになります。
{
"type":"開発",
"title":"ブランドの再定義とコーポレートサイト・製品サイトなど6000ページ超の刷新を支援",
"tag":["UXデザイン", "UIデザイン", "Web開発", "運用・保守"]
}
これに倣ってNo.2〜4まで同様にJSON形式にします。 JSON形式のデータが作成できたら、次はOpenSearchにデータを登録していきます。
まずNo.1のデータを登録してみましょう。 登録には次のコマンドを実行します。
※ コマンド内の次の項目は、「1. ドメインの作成」で作成した”マスターユーザー”の名前とパスワードを設定してください master-user:マスターユーザのユーザー名 master-user-password:マスターユーザのパスワード
※ コマンド内の次の項目は、「Amazon OpenSearch Service > ドメイン > ドメイン名(sample-domain)」画面、”一般的な情報”に記載されている”ドメインエンドポイント”に変更してください。 domain-endpoint:対象ドメインの”ドメインエンドポイント
curl -XPUT -u 'opensearch_master:master-user-password' 'domain-endpoint/projects/_doc/1' -d '{"type":"開発","title":"ブランドの再定義とコーポレートサイト・製品サイトなど6000ページ超の刷新を支援","tag":["UXデザイン", "UIデザイン", "Web開発", "運用・保守"]}' -H 'Content-Type: application/json'
コマンドを実行すると、 “projects” というインデックスが自動で作成され、No.1のドキュメントが登録されます。 ※ 先にインデックス名を指定することも可能です。
こちらが実行結果です。resultがcreatedであるため、登録に成功したことがわかります。
{
"_index":"projects",
"_id":"1",
"_version":1,
"result":"created",
"_shards":
{
"total":2,
"successful":1,
"failed":0
},
"_seq_no":0,
"_primary_term":1
}
続いて、残りのデータを一括で登録してみましょう。 一括で登録する場合は、インデックス名を指定したJSONファイルを作成して登録します。 次のデータをもつJSONファイルを作成し、JSONファイルを保存したディレクトリで、次のコマンドを実行してください。
※ bulk_projects.jsonはファイル名です。設定したファイル名を指定してください。
curl -XPOST -u 'master-user:master-user-password' 'domain-endpoint/_bulk' --data-binary @bulk_projects.json -H 'Content-Type: application/json'
こちらが実行結果です。3データともエラーなく登録されたことがわかります。
{
"took":869,
"errors":false,
"items":[
{"index":{"_index":"projects","_id":"2","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1,"status":201}},
{"index":{"_index":"projects","_id":"3","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1,"status":201}},
{"index":{"_index":"projects","_id":"4","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1,"status":201}
}
]
}
4. 検索
データが登録できたところで、検索してみましょう!
基本的なキーワード検索方法としては、 URLクエリパラメータ /_search?q={キーワード} を用いて検索します。 次のコマンドを実行してみてください。 ここでは"UX"を含むデータを検索します。
curl -XGET -u 'master-user:master-user-password' 'domain-endpoint/projects/_search?q="UX"'
こちらが実行結果です。”UX”を含むデータをもつ4データがヒットしました。
{
"took": 816,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "projects",
"_id": "3",
"_score": 0.2876821,
"_source": {
"type": "事業戦略",
"title": "AR技術などのテクノロジーを活用することにより、顧客のデジタル体験を近代化",
"tag": [
"XR",
"戦略策定",
"サービス設計",
"UXデザイン",
"UIデザイン",
"アプリ開発"
]
}
},
{
"_index": "projects",
"_id": "4",
"_score": 0.2876821,
"_source": {
"type": "成長基盤構築",
"title": "グローバル拠点への情報発信が可能な社内ポータルサイト",
"tag": [
"戦略策定",
"サービス設計",
"UXデザイン",
"UIデザイン",
"PoC支援"
]
}
},
{
"_index": "projects",
"_id": "2",
"_score": 0.2876821,
"_source": {
"type": "開発",
"title": "グローバル拠点への情報発信が可能な社内ポータルサイト",
"tag": [
"UXデザイン",
"UIデザイン",
"Web開発"
]
}
},
{
"_index": "projects",
"_id": "1",
"_score": 0.2876821,
"_source": {
"type": "開発",
"title": "ブランドの再定義とコーポレートサイト・製品サイトなど6000ページ超の刷新を支援",
"tag": [
"UXデザイン",
"UIデザイン",
"Web開発",
"運用・保守"
]
}
}
]
}
}
続いて、より高度な検索を試してみましょう。 OpenSearchではJSON形式でより複雑な設定をした検索を行うことができます。次のクエリを実行してみてください。
curl -XGET -u "master-user:master-user-password" "domain-endpoint/projects/_search" -H "Content-Type: application/json" -d'
{
"query": {
"match": {
"tag": {
"query": "pop支援",
"operator": "and",
"fuzziness": "AUTO"
}
}
}
}'
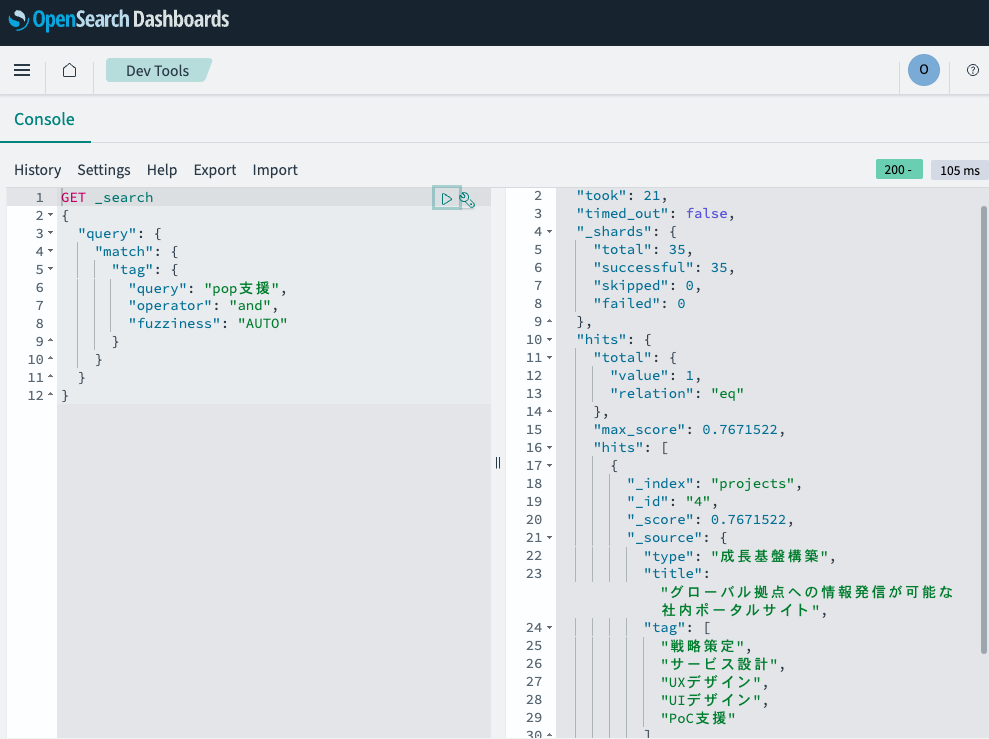
こちらが実行結果です。「pop支援」ではなく、「PoC支援」を含むデータがヒットしました。
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.7671522,
"hits": [
{
"_index": "projects",
"_id": "4",
"_score": 0.7671522,
"_source": {
"type": "成長基盤構築",
"title": "グローバル拠点への情報発信が可能な社内ポータルサイト",
"tag": [
"戦略策定",
"サービス設計",
"UXデザイン",
"UIデザイン",
"PoC支援"
]
}
}
]
}
}
さて、「PoC支援」を含むデータがヒットしたのはなぜでしょうか? ここで、各パラメータの説明をしてみようと思います。
query:
概要: Elasticsearch/OpenSearchにおける検索クエリのトップレベルパラメータです。検索に使用するクエリの種類を指定します。
詳細: queryオブジェクトの中には、検索クエリの種類(例えば、match、termなど)とその条件が記述されます。
match:
概要: 指定されたフィールド内でテキストを検索するために使用されます。これはフルテキスト検索クエリであり、検索テキストをトークン化し、指定されたフィールド内のテキストと比較します。
詳細: このクエリは、検索語が部分的に一致する場合でも、関連するドキュメントを返します。
tag:
概要: matchクエリが検索を行う対象となるフィールドです。この例では「tag」というフィールドが対象です。
詳細: 例えば、記事や投稿にタグ付けされているカテゴリやキーワードなどがtagフィールドに保存されていると仮定します。
query:
概要: matchクエリにおいて、検索するテキストを指定するためのパラメータです。この例では「pop支援」という文字列を検索します。
詳細: Elasticsearchは、この文字列を指定されたフィールドに対して検索し、一致するドキュメントを返します。
operator:
概要: 検索語を複数含む場合に、それらの語を どのように結合するか を決める論理演算子です。
詳細: "or"(デフォルト)だと、検索語のいずれかを含むドキュメントをヒットさせ、"and"だと検索語すべてを含むドキュメントだけをヒットさせます。
fuzziness:
概要: ファジーマッチングの許容度を設定します。ファジーマッチングとは、入力された検索語と似ている単語も検索結果に含める機能です。
詳細: "AUTO"は、検索語の長さに基づいて適切な編集距離を自動的に設定します。例えば、短い単語には1つ、長い単語には2つの編集距離が許容されます。編集距離は、文字の挿入、削除、置換、または隣接する文字の入れ替えの回数を指します。
今回のクエリは、fuzzinessが"AUTO"に設定されているため、 tagフィールドで「pop支援」という単語を検索した結果、似ている「PoC支援」がヒットしました。 この設定はより柔軟な検索結果を提供するため、ユーザーのタイプミス対策に役立ちます。
5. OpenSearch Dashboardsの利用
OpenSearchでは便利なDashboard機能があります。
[AWS] > [Amazon OpenSearch Service] > [ドメイン] > [sample-domain]にアクセスします。 「OpenSearch Dashboards URL (IPv4)」のリンクをクリックし、「1. ドメインの作成」で作成した”マスターユーザー”の名前とパスワードでログインしてください。 下図のような画面が表示されます。
OpenSearch Dashboardsでは、データの管理や可視化、分析が可能です。 例えば、Manage your data > Interact with the OpenSearch APIをクリックしてください。 これまでの手順のようにコマンド等でAPIを利用しなくても登録されたデータに対しクエリを実行し、結果を確認することができます。
6. ドメインの削除
不要になったドメインはちゃんと消しておきましょう! 下記はドメインを"sample-domain"として作成した場合の削除方法です。
① [AWS] > [Amazon OpenSearch Service] > [ドメイン] にアクセスします。 ② [sample-domain]ドメインを選択します。 ③ [削除] ボタンを押下し、削除を確認します。
最後に
本記事ではOpenSearchの基本と構築方法を紹介しました。 検索基盤としての柔軟性やスケーラビリティを活かしつつ、自身の環境に合わせた最適な設計を進めていくことが重要です。 ぜひ実際に試しながら、自分のユースケースに合ったOpenSearchの使い方を見つけてみてください。
Author

Ryuji Takano
ソリューションアーキテクト/エンジニアリングマネージャー
その他おすすめ記事
リモートワークからリモートAIワークへ
いつの間にか、誰も議事録を書かなくなっていました。 Google Meet で Gemini が自動的に文字起こしをして、会議が終わると要約とアクションアイテムを出してくれます。気づいたら、チームの誰もがそれを当たり前のように使っていました。それを読むかどうかは人それぞれです。ただ、『会議で話したことが5分後に要約されたテキストになる』という事実は、最初に見たとき素直に驚きました。 この変化は、働き方の大きな移行の入り口だったと思います。私はこの新たな働き方を、「リモートAIワーク」と定義しました。 この...

EMConf 2026 参加レポート
EMConf 2026 参加レポート 1. はじめに — 参加の動機 3/4に開催された EMConf 2026に参加してきましたので、当日の様子や感想などをレポート形式ご紹介します。 私はエンジニアリングマネージャーとしてフルサイクルチームを立ち上げ、AI駆動を推進しています。 https://engineering.monstar-lab.com/jp/post/2025/10/07/FullCycle-Team-is-launched/ 2. 講演 — 学びと気づき 安斎勇樹さんのキーノート「冒険す...
