Large Language Models are extraordinary generalists, but they fail predictably in two cases: when asked about information they have not seen during training, and when that information has changed since their cut-off date.
Fine-tuning, the practice of further training the model on your own data so it absorbs the specifics of your domain, is one answer to those two failures. It is expensive, slow to iterate, and becomes outdated the moment the underlying data changes. For most teams, what you actually want is a way to give the model fresh, private context at query time. That is what Retrieval-Augmented Generation (RAG) does.
This post walks through RAG in three layers. First, the concepts: what it is, when it wins. Then the best practices that decide whether your prototype survives contact with real users. Finally, a hands-on build on AWS with Amazon Bedrock and OpenSearch Serverless.
What Is RAG?
The idea is simple: when a user asks a question, you first retrieve a small set of relevant documents from a corpus you control, augment the prompt with those documents as context, then generate the answer with the LLM grounded in that context.
The model has not learned anything new. It has been given a better question, one with the answer already in front of it.
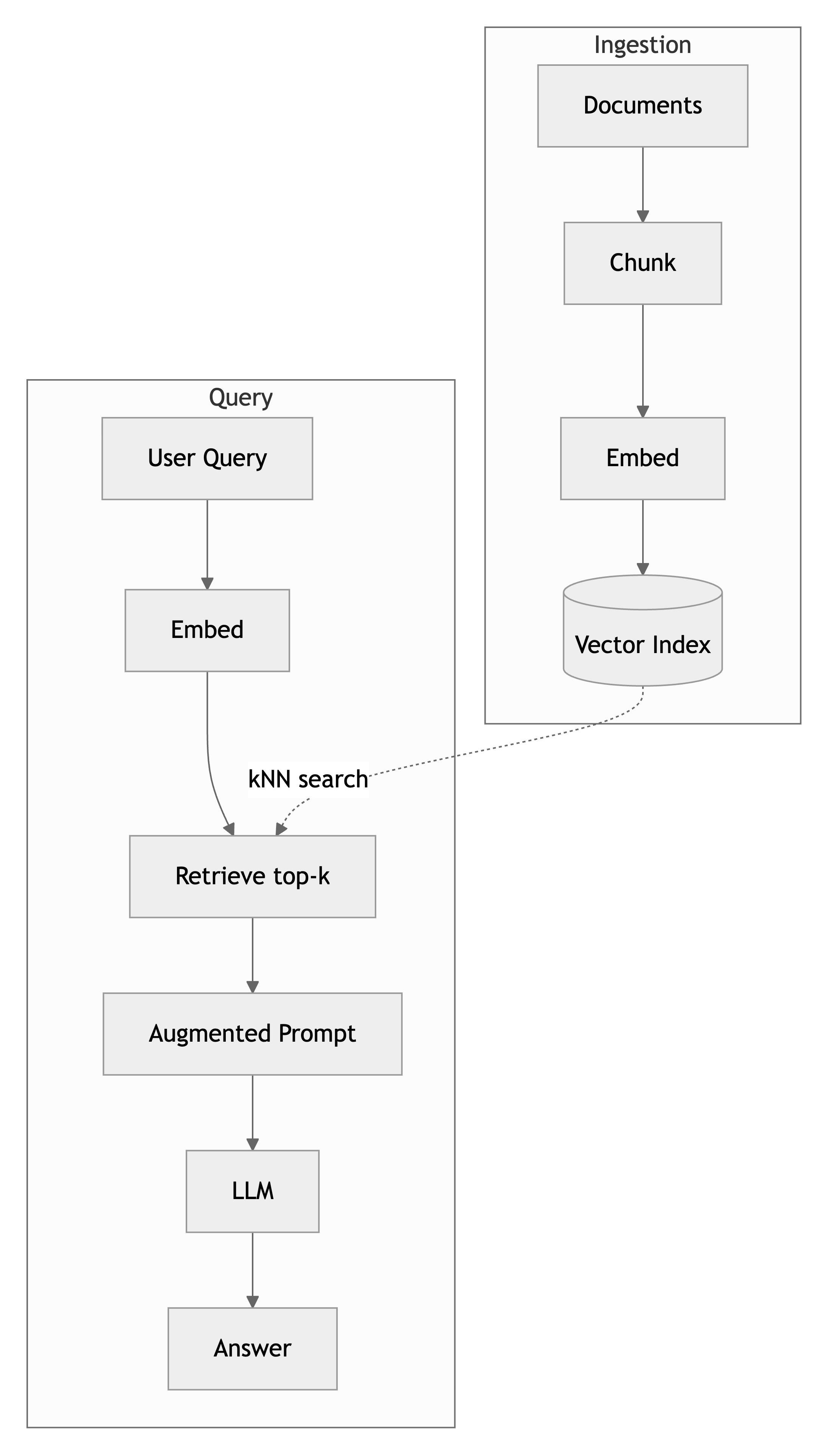
Anatomy of a RAG Pipeline
Every RAG system has two paths.
Ingestion path runs offline, when your corpus changes:
- Chunk documents into passages small enough to fit comfortably in the LLM context window.
- Embed each chunk into a vector using an embedding model.
- Index the vectors in a store that supports approximate nearest-neighbor search.
Query path runs per user request:
- Embed the user's question with the same embedding model.
- Retrieve the top-k most similar chunks from the vector index.
- Generate the answer, passing the retrieved chunks as context in the prompt.
RAG vs Fine-Tuning
| Use case | Best fit | Reason |
|---|---|---|
| Private or domain docs Q&A | RAG | Facts are fetched at query time, so answers stay fresh and sourceable. |
| Consistent tone, style, or format | Fine-tuning | The model learns the behavior directly. |
| Fast-changing support knowledge base | RAG | Reindexing is simpler than retraining. |
| Specialized domain writing | Often both | RAG supplies facts; fine-tuning helps with phrasing and conventions. |
| Strict output schema | Fine-tuning or structured prompting | Behavior control matters more than knowledge retrieval. |
RAG and fine-tuning are not mutually exclusive; many production systems do both. Fine-tune for behavior; retrieve for knowledge.
Best Practices
Retrieval quality is the dominant lever. The practices below are the ones that matter most.
-
Ingest cleanly with structure-aware chunking and rich metadata. Get text extraction right before chunking: PDFs need a text-layer read with an OCR fallback for scanned pages; spreadsheets and HTML need format-specific parsers. Prefer boundary-aware splitting (page breaks first, then paragraphs, then sentences), falling back to fixed-size only when no structure is available. 500 tokens with 50-token overlap is often a reasonable starting point, but tune by document type: smaller chunks for FAQ and support content, larger for dense technical or legal text. Always keep metadata with each chunk (source URL, section, page, last-updated) so you can filter and cite.
-
Pin the embedding model and version per index. An embedding model maps each chunk to a fixed-size vector of floating-point numbers; the dimension is the vector's length (Titan v2 outputs 1024 dimensions). Embedding spaces are not interchangeable, so changing the model means reindexing the entire corpus. Tag each index with the model name, version, and dimension as metadata so query-time embeddings cannot mismatch. Respect the model's input limit: long chunks get silently truncated unless you split them first.
-
Retrieve with hybrid search, reranking, and a tuned kNN index. Vector search alone struggles with proper nouns, exact phrases, and rare terms. Combine vector similarity with BM25 keyword scoring for hybrid search. Tune top-k per query type; it is not a constant. Add a reranker (a cross-encoder like Cohere Rerank or a fine-tuned one of your own) over the top 20 to 50 candidates and keep the top 3 to 5 after reranking. The kNN index has parameters worth tuning: HNSW
m(graph connectivity, default 16),ef_construction(build accuracy, commonly 256 to 512), andef_search(query-time accuracy vs latency). Follow your embedding model's documented similarity metric (cosinesimilfor normalized embeddings is common; some models prescribe dot product or L2). -
Design refusal, citation, and validation into the response path. Decide explicitly what happens when retrieval returns nothing relevant: the model should refuse, not improvise. Number your context chunks and instruct the model to cite them: "Answer using only the context. Cite sources as [1], [2]." For strict output schemas, prefer the model's function-calling or structured-output API over prompt heuristics or fine-tuning, and combine it with a downstream validator for anything that drives programmatic actions. Sanitize untrusted retrieved text: it can carry prompt injection, so strip control tokens and filter PII out of both indexed content and outputs.
-
Evaluate, budget, and operate. You cannot improve what you do not measure. Build a small golden set (50 to 200 question-answer pairs) on day one, and measure two things separately: retrieval recall@k (is the right chunk in the top-k?) and generation faithfulness (does the answer rely only on retrieved context?). RAG is metered: embedding 100k chunks at $0.10/1M tokens is one cost; generating answers with a frontier model is another. Set a latency budget per stage (embed: <100ms, retrieve: <50ms, generate: <2s) and instrument each one. Decide how fresh the index needs to be: incremental upserts on write are simpler than full nightly reindexes but require more plumbing.
Building It on AWS
Let's walk through a minimal end-to-end RAG service on AWS using Amazon Bedrock for embeddings and generation, and Amazon OpenSearch Serverless for vector retrieval.
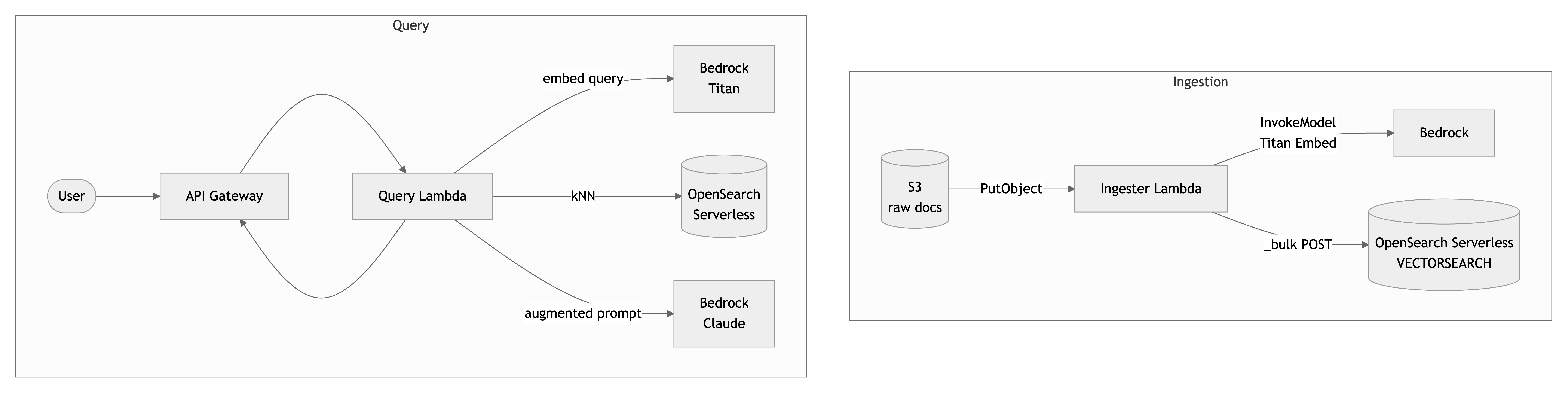
Components:
- S3: raw documents land here.
- Ingester Lambda: triggered on S3 PutObject; chunks, embeds via Bedrock, indexes into OpenSearch.
- OpenSearch Serverless: vector collection of type
VECTORSEARCH. - API Gateway + Query Lambda: public query endpoint; embeds the question, runs kNN, calls Bedrock with the augmented prompt.
- Bedrock:
amazon.titan-embed-text-v2:0for embeddings,anthropic.claude-3-5-sonnetfor generation.
OpenSearch Serverless (Terraform)
resource "aws_opensearchserverless_security_policy" "encryption" {
name = "${var.app.prefix}-rag-enc"
type = "encryption"
policy = jsonencode({
Rules = [{
Resource = ["collection/${var.app.prefix}-rag"]
ResourceType = "collection"
}]
AWSOwnedKey = true
})
}
resource "aws_opensearchserverless_collection" "rag" {
name = "${var.app.prefix}-rag"
type = "VECTORSEARCH"
depends_on = [aws_opensearchserverless_security_policy.encryption]
}
Network and data-access policies follow the same pattern. The collection exposes an HTTPS endpoint your Lambdas authenticate to via SigV4.
Ingester Lambda (Go)
func handler(ctx context.Context, evt events.S3Event) error {
for _, rec := range evt.Records {
body, err := s3Get(ctx, rec.S3.Bucket.Name, rec.S3.Object.Key)
if err != nil {
return fmt.Errorf("s3 get: %w", err)
}
chunks := chunkText(string(body), 500, 50)
vecs, err := embedAll(ctx, chunks, 8)
if err != nil {
return fmt.Errorf("embed: %w", err)
}
if err := aossBulkIndex(ctx, rec.S3.Object.Key, chunks, vecs); err != nil {
return fmt.Errorf("index: %w", err)
}
}
return nil
}
embedAll runs bedrock:InvokeModel calls in parallel with a bounded worker pool and returns vectors in chunk order. aossBulkIndex issues one SigV4-signed POST /_bulk for all chunk/vector pairs. Each indexed document has shape {"text": chunk, "embedding": vec, "source": key}.
Query Lambda (Go)
func handler(ctx context.Context, req events.APIGatewayProxyRequest) (*events.APIGatewayProxyResponse, error) {
var body struct {
Question string `json:"question"`
}
if err := json.Unmarshal([]byte(req.Body), &body); err != nil {
return utils.BadRequest("invalid json"), nil
}
qvec, err := bedrockEmbed(ctx, body.Question)
if err != nil {
return nil, fmt.Errorf("embed query: %w", err)
}
chunks, err := aossKNN(ctx, qvec, 5)
if err != nil {
return nil, fmt.Errorf("retrieve: %w", err)
}
prompt := buildPrompt(body.Question, chunks)
answer, err := bedrockGenerate(ctx, prompt)
if err != nil {
return nil, fmt.Errorf("generate: %w", err)
}
return utils.SuccessResponse(200, map[string]any{
"answer": answer,
"sources": chunkSources(chunks),
}), nil
}
buildPrompt numbers the retrieved chunks and instructs Claude to cite them. aossKNN runs an OpenSearch knn query against the embedding field.
Suggested Next Steps
- Add reranking. Plug a cross-encoder call between
aossKNNandbuildPrompt. - Add hybrid search. OpenSearch supports it natively: combine a
knnquery with amatchclause and tune the weights. - Add evaluation. Keep a small set of test questions with known good answers and rerun them after each change, so you can tell whether retrieval and answers are getting better or worse.
Conclusion
RAG is one of the highest-leverage patterns in applied LLM work: easy to start, hard to get right at scale. The concepts are simple, the best practices are where production lives, and the AWS build above is a starting line, not a finish.
If you build on this, the two follow-ups worth their own posts are evaluation (how to know your retrieval is actually getting better) and reranking (the single biggest precision lever after hybrid search). Those are the two areas that usually decide whether a RAG system stays a demo or becomes reliable in production.
References
Author

You may also like
Serverpod for a Weekend - The Good, The Bad, and The Surprising
I've been building Flutter apps professionally for years now, and I've seen the backend landscape evolve from Firebase to Supabase to custom Node.js APIs. Each solution came with trade-offs: Firebase locked you in, Supabase was great until you needed cust...

What I Thought Was People Management Wasn't People Management at All
This article is the 15th entry in the D-Plus🐬 Development Productivity Community Advent Calendar 2025. Day 14's article is... wait, nobody's there??? I had the opportunity to speak at D-Plus in Osaka back in May with a presentation called Task Management...
