In today's fast-paced data-driven world, real-time data processing has become indispensable for businesses across various sectors.
From monitoring system performance to analyzing customer behavior, the ability to process data in real-time offers invaluable insights for timely decision-making.
However, one critical aspect often overlooked is handling failures gracefully in real-time data processing pipelines.
In this part of our series, we will explore the importance of implementing robust retry strategies.
Important Note: AWS has announced that AWS App Mesh will be discontinued in September 2026. While App Mesh remains fully supported until then, you should consider AWS Service Connect instead. AWS Service Connect provides similar functionality with improved performance and simplified configuration.
Part 1: AWS ECS App Mesh and Retry Strategies
Amazon Elastic Container Service (ECS) is a fully managed container orchestration service that allows you to run, stop, and manage Docker containers on a cluster. It eliminates the need to install, operate, and scale a cluster management infrastructure.
AWS App Mesh belongs to the category of service meshes, which are specialized infrastructure layers designed to manage communication between services within a distributed application architecture.
Essentially, AWS App Mesh simplifies the networking aspect of your applications by offering features like service discovery, load balancing, encryption, authentication, and observability.
In essence, AWS App Mesh streamlines communication between microservices, allowing developers to focus on building application logic rather than worrying about networking setup.
This approach enhances the reliability, security, and observability of modern distributed systems. Other popular service mesh implementations include Istio and Linkerd.
AWS App Mesh, in conjunction with Amazon ECS, offers a robust platform for deploying microservices architectures that are well-suited for real-time data processing.
While App Mesh offers features like service discovery, traffic management, and observability, its inherent ability to handle failures through retry policies is crucial for ensuring data integrity and system reliability.
Importance of Retry Strategies
In real-time data processing, failures are inevitable due to network issues, service disruptions, or transient errors.
Therefore, implementing effective retry strategies becomes crucial. Here are some key aspects to consider:
-
Determining Retry Attempts: Deciding the number of retry attempts depends on factors like the criticality of the data, the likelihood of transient failures, and the impact on downstream processes. It's essential to find a balance between ensuring data delivery and avoiding endless retries, which could lead to resource exhaustion.
-
Exponential Backoff: Adopting exponential backoff strategies can prevent overwhelming downstream systems during high-load scenarios. Gradually increasing the time between retry attempts reduces the likelihood of further failures.
-
Dead Letter Queues (DLQ): Implementing DLQs allows you to capture failed messages for further analysis and manual intervention. It's crucial to set up robust monitoring and alerting mechanisms to promptly address issues identified in the DLQ.
Testing App Mesh Retry Policy
Let's put the App Mesh retry policy to the test by simulating failure scenarios in a real-time data processing pipeline.
We'll set up two services: a Data Ingestion service and a Data Processing service using Terraform.
-
Data Ingestion Service: This service receives data from external sources and forwards it to the processing pipeline.
-
Data Processing Service: This service analyzes incoming data in real-time, performing tasks such as anomaly detection or aggregation.
Terraform Configuration
We'll use Terraform to define the infrastructure for the Data Ingestion service and Data Processing service, along with the App Mesh configuration.
We will omit the full Terraform configuration for brevity, but here's a high-level overview of the key components:
- App Mesh
Let's start with the core components of the app mesh.
- Service Mesh: The logical boundary for the services that make up the app mesh itself.
resource "aws_appmesh_mesh" "app-mesh" {
name = "${var.env}-${var.project}-app-mesh"
spec {
egress_filter {
type = "DROP_ALL" # Allow only egress from virtual nodes to other resources within the mesh
}
}
}
- Virtual Service: Abstract representation of the Data Ingestion service and the Data Processing service running in the mesh.
# data-processing virtual service
resource "aws_appmesh_virtual_service" "data-processing-service" {
name = "${local.services.data-processing}.${var.env}.${var.internal_domain}"
mesh_name = aws_appmesh_mesh.app-mesh.id
spec {
provider {
virtual_router {
virtual_router_name = aws_appmesh_virtual_router.data-processing-service.name
}
}
}
}
# data-ingestion virtual service
# ...
The virtual router is responsible for handling traffic for the virtual service. It is defined later in the configuration with routing rules and retry policies for the virtual service.
- Virtual Node: Concrete implementations behind the abstracted virtual services. Each virtual node points to a specific ECS service, where actual code runs.
# data-ingestion virtual node
resource "aws_appmesh_virtual_node" "data-ingestion-service" {
name = "${var.env}-${var.project}-data-ingestion-service"
mesh_name = aws_appmesh_mesh.app-mesh.id
spec {
backend {
virtual_service {
virtual_service_name = aws_appmesh_virtual_service.data-processing-service.name
}
}
listener {
port_mapping {
port = var.ecs_services["data-ingestion"].app_port
protocol = "http"
}
timeout {
http {
per_request {
value = var.ecs_services["data-ingestion"].app_mesh_timeout.value
unit = var.ecs_services["data-ingestion"].app_mesh_timeout.unit
}
}
}
}
service_discovery {
aws_cloud_map {
service_name = aws_appmesh_virtual_service.data-processing-service.name
namespace_name = aws_service_discovery_private_dns_namespace.internal.name
}
}
logging {
access_log {
file {
path = "/dev/stdout"
}
}
}
}
}
# data-processing virtual node
# ...
In this example, we have defined the virtual nodes for the Data Processing service and the Data Ingestion service.
In the Data Ingestion virtual node, we have defined the Data Processing virtual service as the backend to which the virtual node is expected to send outbound traffic.
We have specified the listener for the virtual nodes, which defines the port and protocol for incoming traffic.
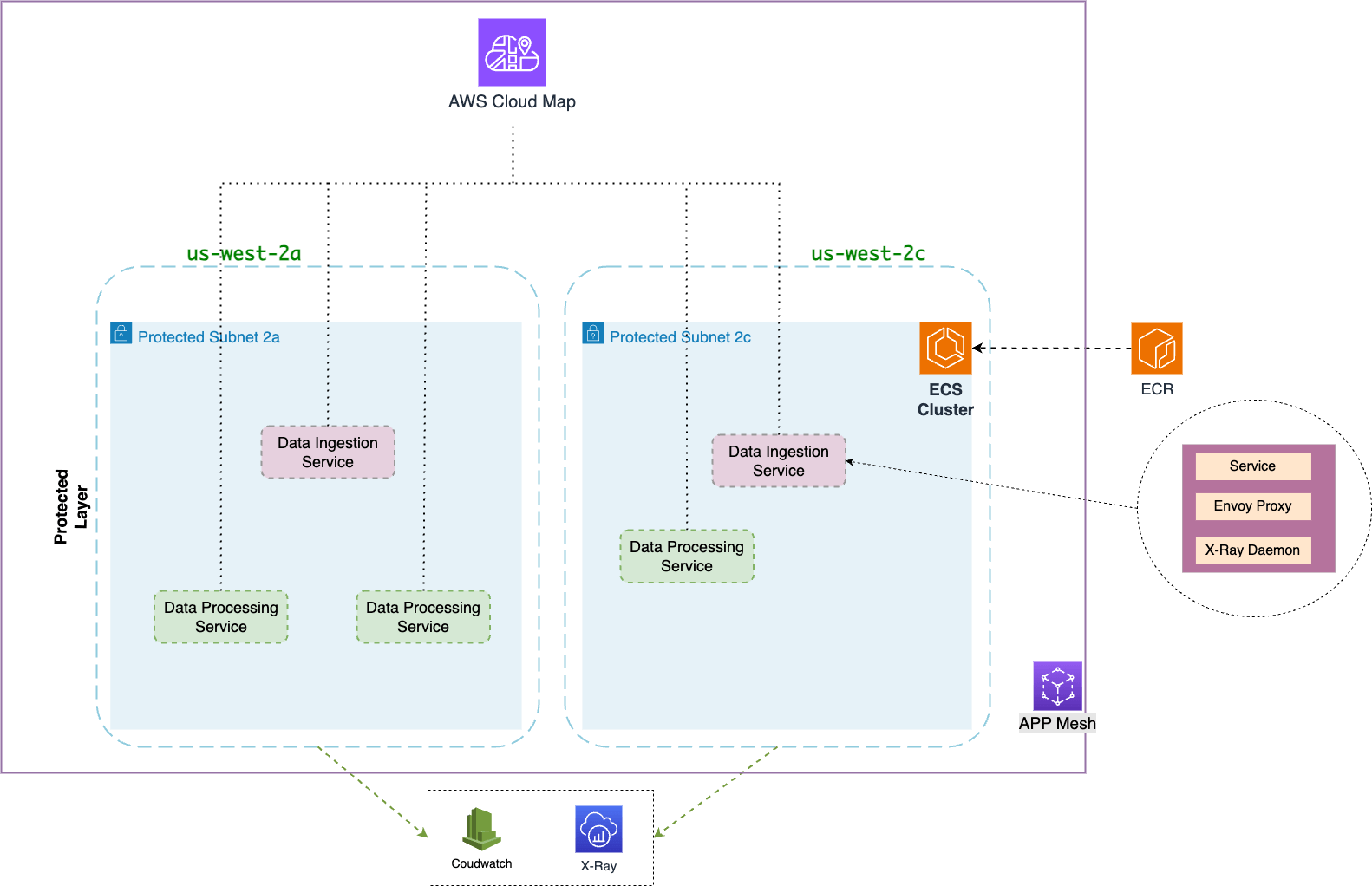
We have also specified the service discovery mechanism for the virtual node, which in this case is AWS Cloud Map.
- Route: Specifies how traffic flows between services. You can define routing rules based on various criteria like service name, attributes, or weighted distribution.
# data-processing App Mesh virtual router
resource "aws_appmesh_virtual_router" "data-processing-service" {
name = "${var.env}-${var.project}-data-processing-service-virtual-router"
mesh_name = aws_appmesh_mesh.app-mesh.id
spec {
listener {
port_mapping {
port = var.ecs_services["data-processing"].app_port
protocol = "http"
}
}
}
}
# data-processing service App Mesh route
resource "aws_appmesh_route" "data-processing-service" {
name = "${var.env}-${var.project}-data-processing-service"
mesh_name = aws_appmesh_mesh.app-mesh.id
virtual_router_name = aws_appmesh_virtual_router.data-processing-service.name
spec {
http_route {
match {
prefix = "/"
}
retry_policy {
http_retry_events = [
"gateway-error",
]
max_retries = 12
per_retry_timeout {
unit = "s"
value = 5
}
tcp_retry_events = [
"connection-error",
]
}
action {
weighted_target {
virtual_node = aws_appmesh_virtual_node.data-processing-service.name
weight = 1
}
}
}
priority = 1
}
}
# data-ingestion service App Mesh virtual router
# ...
# data-ingestion service App Mesh route
# ...
We have defined the route to match any incoming HTTP traffic and route it with retries to the Data Processing service virtual node.
The retry policy specifies that the service should retry on gateway errors and connection errors, with a maximum of 12 retries and a per-retry timeout of 5 seconds.
Note that the action specifies the weighted target, which is the virtual node to which the traffic should be routed. We have set the weight to 1, indicating that all traffic should be routed to the Data Processing service virtual node.
Note that when defining virtual services, we could have used a virtual node as the provider for the virtual service and omitted a virtual router, which would not provide granular control over the routing rules.
# data-processing virtual service
resource "aws_appmesh_virtual_service" "data-processing-service" {
name = "${local.services.data-processing}.${var.env}.${var.internal_domain}"
mesh_name = aws_appmesh_mesh.app-mesh.id
spec {
provider {
virtual_node {
virtual_node_name = aws_appmesh_virtual_node.data-processing-service.name
}
}
}
}
- Cloud Map Service Discovery: This allows services to discover and communicate with each other using custom DNS names.
# Private DNS Namespace
resource "aws_service_discovery_private_dns_namespace" "internal" {
name = "${var.env}.${var.internal_domain}"
description = "${var.env}-${var.project}-private-dns-namespace"
vpc = var.aws_vpc-vpc-id
}
# data-processing
resource "aws_service_discovery_service" "data-processing" {
name = local.services.data-processing
dns_config {
namespace_id = aws_service_discovery_private_dns_namespace.internal.id
dns_records {
ttl = 10
type = "A"
}
routing_policy = "MULTIVALUE"
}
health_check_custom_config {
failure_threshold = 1
}
lifecycle {
create_before_destroy = true
}
}
- AWS ECS
We'll now define the ECS cluster configuration for the Data Ingestion service and the Data Processing service.
- ECS Cluster
# ECS cluster
resource "aws_ecs_cluster" "ecs-cluster" {
name = "${var.env}-${var.project}-ecs-cluster"
setting {
name = "containerInsights"
value = "enabled"
}
}
# ECS cluster capacity provider
resource "aws_ecs_cluster_capacity_providers" "ecs-cluster" {
cluster_name = aws_ecs_cluster.ecs-cluster.name
capacity_providers = ["FARGATE"]
default_capacity_provider_strategy {
weight = 1
capacity_provider = "FARGATE"
}
}
- ECS Services
# data-processing
resource "aws_ecs_service" "data-processing-service" {
name = local.services.data-processing
cluster = aws_ecs_cluster.ecs-cluster.id
task_definition = aws_ecs_task_definition.ecs-data-processing-task.arn
launch_type = "FARGATE"
deployment_maximum_percent = var.ecs_services["data-processing"].deployment_maximum_percent
deployment_minimum_healthy_percent = var.ecs_services["data-processing"].deployment_minimum_healthy_percent
desired_count = var.ecs_services["data-processing"].desired_count
force_new_deployment = true
lifecycle {
ignore_changes = [desired_count, task_definition]
}
network_configuration {
subnets = var.aws_subnet-protected-ids
security_groups = [aws_security_group.ecs-service.id]
}
service_registries {
registry_arn = aws_service_discovery_service.data-processing.arn
}
}
# data-ingestion
# ...
We have created the ECS cluster and defined the ECS services for the Data Processing and Data Ingestion services.
- Task Definition
# data-processing task definition
resource "aws_ecs_task_definition" "ecs-data-processing-task" {
family = "${var.env}-${var.project}-data-processing-service"
requires_compatibilities = ["FARGATE"]
cpu = var.ecs_services["data-processing"].task_definition.cpu
memory = var.ecs_services["data-processing"].task_definition.memory
network_mode = "awsvpc"
execution_role_arn = aws_iam_role.task-exec.arn
task_role_arn = aws_iam_role.ecs-task.arn
container_definitions = jsonencode([
{
name = "data-processing-service"
image = "${aws_ecr_repository.data-processing-service.repository_url}:${var.app_version}"
essential = true
environment = [
{
name = "APP_PORT"
value = tostring(var.ecs_services["data-processing"].app_port)
}
]
portMappings = [
{
containerPort = var.ecs_services["data-processing"].app_port
protocol = "tcp"
}
]
healthCheck = {
command = [
"CMD-SHELL",
"curl -s http://localhost:${var.ecs_services["data-processing"].app_port}/health-check || exit 1"
]
interval = 20
retries = 5
startPeriod = 10
timeout = 5
}
depends_on = [
{
"containerName" : "envoy",
"condition" : "HEALTHY"
}
]
logConfiguration = {
logDriver = "awslogs"
options = {
awslogs-group = aws_cloudwatch_log_group.data-processing-service.name
awslogs-region = var.region
awslogs-stream-prefix = "awslogs-data-processing"
}
}
},
{
name = "envoy"
image = "000000000000.dkr.ecr.${data.aws_region.current.name}.amazonaws.com/aws-appmesh-envoy:v1.27.2.0-prod"
essential = true
cpu = var.ecs_services["data-processing"].task_definition.envoy_cpu
memory = var.ecs_services["data-processing"].task_definition.envoy_memory
environment = [
{
name = "APPMESH_RESOURCE_ARN",
value = aws_appmesh_virtual_node.data-processing-service.arn
},
{
name = "ENVOY_LOG_LEVEL",
value = "info"
},
{
name = "ENVOY_INITIAL_FETCH_TIMEOUT",
value = "30"
},
{
name = "ENABLE_ENVOY_XRAY_TRACING",
value = "1"
},
]
portMappings = [
{
protocol = "tcp",
containerPort = 9901
},
{
protocol = "tcp",
containerPort = 15000
},
{
protocol = "tcp",
containerPort = 15001
}
]
healthCheck = {
command = [
"CMD-SHELL",
"curl -s http://localhost:9901/server_info | grep state | grep -q LIVE"
],
interval = 5,
retries = 3,
startPeriod = 60,
timeout = 2
}
user = "1337"
logConfiguration = {
logDriver = "awslogs"
options = {
awslogs-group = aws_cloudwatch_log_group.data-processing-service.name
awslogs-region = var.region
awslogs-stream-prefix = "awslogs-envoy-data-processing"
}
}
},
{
name = "xray-daemon"
image = "public.ecr.aws/xray/aws-xray-daemon:latest"
essential = false
cpu = var.ecs_services["data-processing"].task_definition.xray_cpu
memoryReservation = var.ecs_services["data-processing"].task_definition.xray_memory
portMappings = [
{
hostPort = 2000
containerPort = 2000
protocol = "udp"
}
]
user = "1337"
logConfiguration = {
logDriver = "awslogs"
options = {
awslogs-group = aws_cloudwatch_log_group.data-processing-service.name
awslogs-region = var.region
awslogs-stream-prefix = "awslogs-xray-data-processing"
}
}
}
])
proxy_configuration {
type = "APPMESH"
container_name = "envoy"
properties = {
AppPorts = var.ecs_services["data-processing"].app_port
EgressIgnoredIPs = "169.254.170.2,169.254.169.254"
IgnoredUID = "1337"
ProxyEgressPort = 15001
ProxyIngressPort = 15000
EgressIgnoredPorts = 22
}
}
}
# data-ingestion task definition
# ...
The Data Processing and Data Ingestion services task definitions include:
-
Individual container configurations: This includes specifying the image used, necessary environment variables, port mappings for communication, health checks to ensure proper functioning, and logging setups for analysis.
-
App Mesh integration: The defined proxy configuration enables the Envoy sidecar proxy to intercept and route both incoming and outgoing traffic through the App Mesh service mesh. Envoy acts as a high-performance data plane component, essentially managing the network interactions within the mesh. For deeper understanding, please refer to the official Envoy documentation.
-
Distributed tracing: The inclusion of a xray-daemon container allows for tracing the flow of requests across various services, providing valuable insights into system performance and potential issues via AWS X-Ray.
Here's a high-level overview of the Terraform configuration for the Data Ingestion and the Data Processing services.
Backend Services
Let's proceed to develop the backend applications for the Data Ingestion and Data Processing services using Golang.
- Data Ingestion Service
func main() {
// Create a new router
router := mux.NewRouter()
// Define routes
router.HandleFunc("/health-check", HealthCheckHandler).Methods("GET")
router.HandleFunc("/ev", ElectricVehicleHandler).Methods("POST")
// Start the server
log.Fatal(http.ListenAndServe(":3000", router))
}
// ElectricVehicleHandler handles the /ev endpoint
func ElectricVehicleHandler(w http.ResponseWriter, r *http.Request) {
log.Printf("Request: %s %s", r.Method, r.URL.Path)
// Read request body
body, err := io.ReadAll(r.Body)
if err != nil {
log.Println(err)
http.Error(w, "Failed to read request body", http.StatusInternalServerError)
return
}
// Decode JSON payload
var payload ElectricVehiclePayload
err = json.Unmarshal(body, &payload)
if err != nil {
log.Println(err)
http.Error(w, "Failed to decode JSON payload", http.StatusBadRequest)
return
}
// Do whatever pre-processing is required
// ...
// Create a request to the data processing service endpoint
req, err := http.NewRequest("POST", dataProcessingEndpoint, bytes.NewBuffer(body))
if err != nil {
log.Println(fmt.Errorf("failed to create request to data processing service: %w", err))
http.Error(w, "Failed to POST to data processing service", http.StatusInternalServerError)
return
}
// Clone headers from the incoming request to the outgoing request
req.Header = r.Header.Clone()
// HTTP POST request to data processing service
resp, err := http.DefaultClient.Do(req)
if err != nil {
log.Println(fmt.Errorf("failed to create request to data processing service: %w", err))
http.Error(w, "Failed to POST to data processing service", http.StatusInternalServerError)
return
}
// Check if response status code is not 200
if resp.StatusCode != http.StatusOK {
msg := fmt.Sprintf("Data processing service returned non-200 status code: %d", resp.StatusCode)
log.Print(msg)
http.Error(w, msg, resp.StatusCode)
return
}
// Copy the response from the data processing service to the current response writer
_, err = io.Copy(w, resp.Body)
if err != nil {
log.Println(err)
http.Error(w, "Failed to copy response", http.StatusInternalServerError)
return
}
}
The Data Ingestion service is a simple HTTP server that listens for incoming POST requests via the /ev endpoint.
This service is supposed to receive data from external sources (Electric Vehicle data in this case).
In this example, we've defined the ElectricVehicleHandler function to handle incoming EV data. It decodes the JSON payload, performs any pre-processing required, and forwards the request to the Data Processing service.
- Data Processing Service
func main() {
// Create a new router
router := mux.NewRouter()
// Define routes
router.HandleFunc("/health-check", HealthCheckHandler).Methods("GET")
router.HandleFunc("/ev", ElectricVehicleDataProcessingHandler).Methods("POST")
// Start the server
log.Fatal(http.ListenAndServe(":3000", router))
}
// ElectricVehicleDataProcessingHandler handles EV data
func ElectricVehicleDataProcessingHandler(w http.ResponseWriter, r *http.Request) {
// Log the request
log.Printf("Request: %s %s", r.Method, r.URL.Path)
// return 503 if x-503 header is set
if value, ok := r.Header["X-503"]; ok {
log.Printf("X-503 header is set with values: %v", value)
w.WriteHeader(http.StatusServiceUnavailable)
_, err := w.Write([]byte("Data Processing Service will return 503 ==> called with x-503 header set."))
if err != nil {
log.Println(err)
}
return
}
// Read request body
body, err := io.ReadAll(r.Body)
if err != nil {
log.Println(err)
http.Error(w, "Failed to read request body", http.StatusInternalServerError)
return
}
// Decode JSON payload
var payload ElectricVehiclePayload
err = json.Unmarshal(body, &payload)
if err != nil {
log.Println(err)
http.Error(w, "Failed to decode JSON payload", http.StatusBadRequest)
return
}
// Process the payload
// ...
// Response back to the client
w.WriteHeader(http.StatusOK)
_, err = w.Write([]byte("Payload processed successfully"))
if err != nil {
log.Println(err)
return
}
}
The Data Processing Service is also a simple HTTP server that listens for incoming POST requests via the /ev endpoint.
To simulate a failure scenario, the ElectricVehicleDataProcessingHandler function returns a 503 status code if the x-503 header is set.
This service is supposed to analyze incoming data in real-time, performing tasks such as anomaly detection or aggregation.
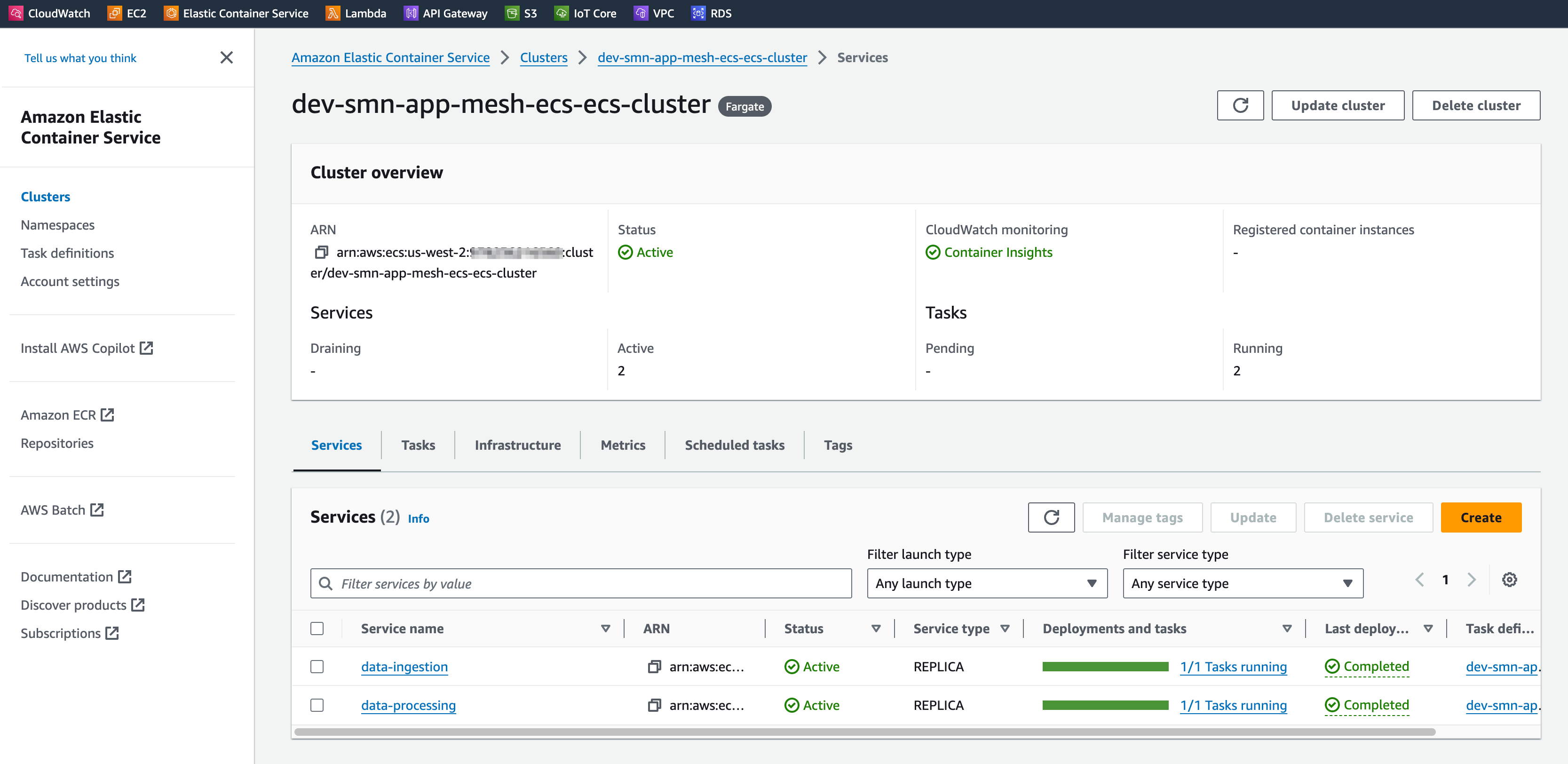
After running terraform apply and deploying the backend services, we can check from the Dashboard that the services are running and healthy.
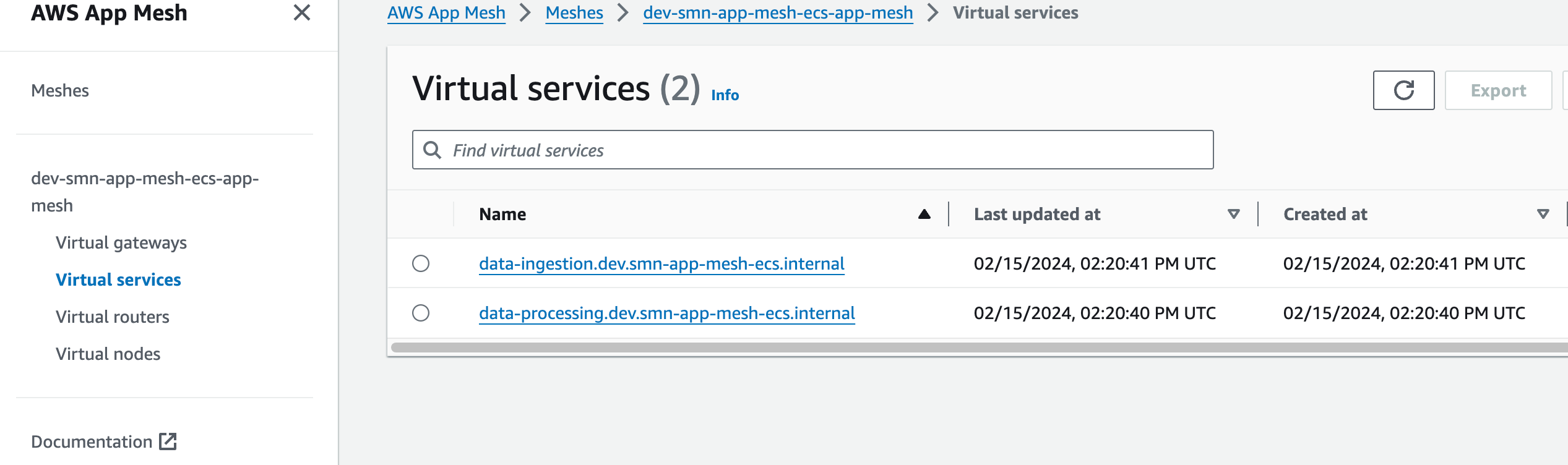
and the App Mesh configuration is also set up correctly.
Simulating Failure Scenarios
We'll simulate failure scenarios by passing the x-503 header to the Data Processing service, causing it to return a 503 status code.
Using AWS Session Manager to get inside the protected subnet, let's first confirm that calls to our services are going through the envoy proxy.
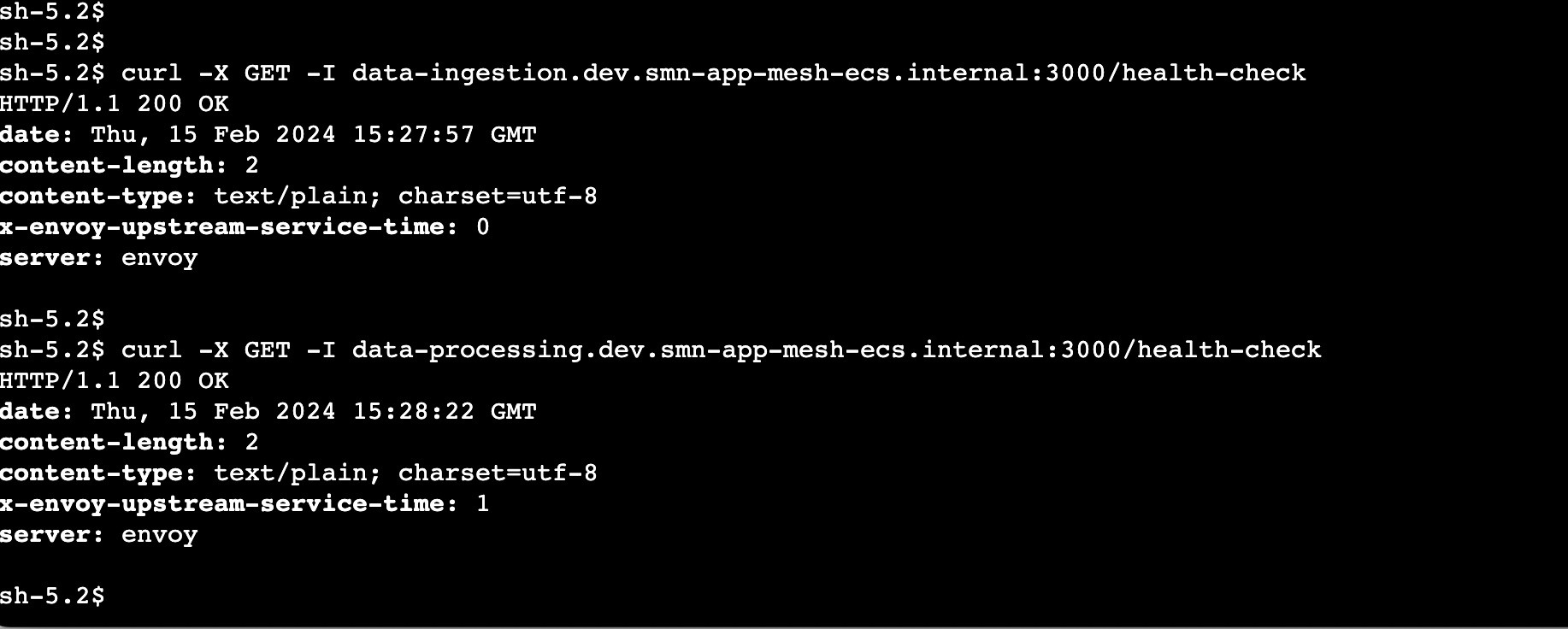
We can see that services are healthy and calls are going through the envoy proxy.
-
server: envoy: Indicates that the request is being handled by the Envoy Proxy. -
x-envoy-upstream-service-time: 1: Indicates the time (in milliseconds) taken by Envoy Proxy to communicate with the upstream service (backend services in this case).
Now, we'll call the Data Ingestion service with the x-503 header set, and observe the behavior of the App Mesh retry policy.
curl --location 'http://data-ingestion.dev.smn-app-mesh-ecs.internal:3000/ev' \
--header 'Content-Type: application/json' \
--header 'x-503: true' \
--data '{
"vehicle_id": "EV-001",
"timestamp": "2024-02-15T10:30:00Z",
"location": {
"latitude": 37.7749,
"longitude": -122.4194
},
"battery": {
"percentage": 75,
"voltage": 390,
"temperature": 25.3
},
"speed": 60,
"odometer": 12500
}
'
- Data Ingestion service logs:

- Data Processing service logs:
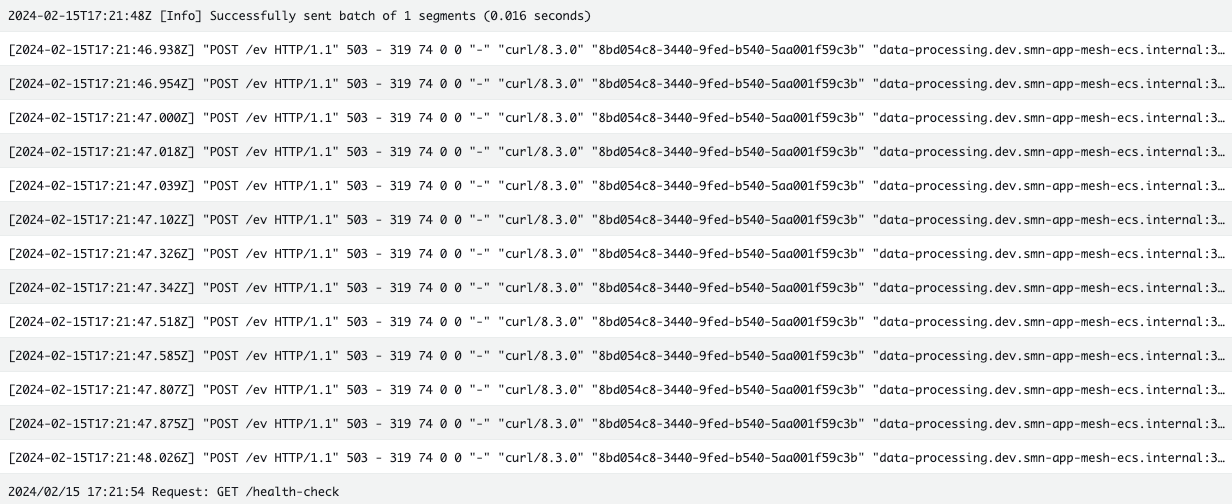
For a single request sent to the Data Ingestion service, we observed that the Data Processing service returned a 503 status code. Consequently, the request was retried 12 times in accordance with the retry policy.
In this case, since the Data Processing service is implemented to return a 503 status code when the x-503 header is set, the request failed after 12 retries.
In a real-world scenario, the Data Processing service would eventually recover from the transient failure, and the request would be successfully processed.
In the absence of the App Mesh retry policy, the request to the Data Processing service would have failed, and the Data Ingestion service would have returned an error to the client.
It's worth noting that in the absence of the App Mesh retry policy, one would have implemented an HTTP retry mechanism in the Data Ingestion Golang code. Utilizing the App Mesh retry policy offers a more robust and centralized approach, allowing developers to focus on application logic rather than network setup concerns.
Conclusion
Incorporating retry strategies is imperative for ensuring the resilience and reliability of real-time data communication between microservices.
With AWS ECS App Mesh, coupled with effective retry policies, organizations can mitigate the impact of failures and uphold data integrity in critical business processes.
In the next part of our series, we will explore additional crucial elements of real-time data processing.
Author

You may also like
Serverpod for a Weekend - The Good, The Bad, and The Surprising
I've been building Flutter apps professionally for years now, and I've seen the backend landscape evolve from Firebase to Supabase to custom Node.js APIs. Each solution came with trade-offs: Firebase locked you in, Supabase was great until you needed cust...

What I Thought Was People Management Wasn't People Management at All
This article is the 15th entry in the D-Plus🐬 Development Productivity Community Advent Calendar 2025. Day 14's article is... wait, nobody's there??? I had the opportunity to speak at D-Plus in Osaka back in May with a presentation called Task Management...
